Equilibrium Propagation: Bridging the Gap Between Energy-Based Models and Backpropagation
作者: Benjamin Scellier, Yoshua Bengio
日期: 2017年3月
1. 摘要 (Abstract)
本文提出了 Equilibrium Propagation (均衡传播),这是一种用于训练基于能量的模型(Energy-Based Models, EBMs)的学习框架。该框架的核心优势在于:
* 统一的计算机制:训练的两个阶段(预测阶段和目标误差揭示后的第二阶段)使用相同的神经计算机制。
* 无需特殊电路:与反向传播(Backpropagation, BP)不同,EqProp 不需要专门的电路来传播误差导数。误差是通过系统向更低能量状态的弛豫隐式传播的。
* 理论完备性:解决了 Contrastive Hebbian Learning (CHL) 和 Contrastive Divergence (CD) 的理论缺陷,能够计算定义良好的目标函数的梯度。
* 生物学合理性:第二阶段对应于将预测(固定点)向减少预测误差的方向进行微小的“推移”(nudging)。这种机制使得类 BP 的学习在生物大脑中实现成为可能。
2. 连续 Hopfield 模型重访 (The Continuous Hopfield Model Revisited)
EqProp 可以被视为一种更具生物学合理性的反向传播形式。它引入了一个新的学习框架来训练连续 Hopfield 模型。
2.1 能量函数 (Energy Function)
网络状态由单元集合 $u$ 表示,参数为 $\theta = (W, b)$。能量函数 $E$ 定义为:
$$E(u) := \frac{1}{2} \sum_{i} u_i^2 - \frac{1}{2} \sum_{i \neq j} W_{ij} \rho(u_i) \rho(u_j) - \sum_{i} b_i \rho(u_i)$$
其中:
* $u_i$ 是单元 $i$ 的状态(如膜电位)。
* $\rho(u_i)$ 是非线性激活函数(如放电率)。
* $W_{ij}$ 是对称的突触权重 ($W_{ij} = W_{ji}$)。
* $b_i$ 是偏置。
在监督学习设定中,单元被分为输入 $x$(始终被钳制)、隐藏单元 $h$ 和输出单元 $y$。即 $u = \{x, h, y\}$。
目标是让输出 $y$ 接近目标 $y$。代价函数(Cost Function)定义为:
$$C := \frac{1}{2} \|y - y\|^2$$
引入 总能量函数 (Total Energy Function) $F$,结合了内部能量 $E$ 和外部代价 $C$:
$$F := E + \beta C$$
其中 $\beta \ge 0$ 是影响参数(influence parameter),控制输出单元被目标“钳制”的程度。
2.2 神经动力学 (Neuronal Dynamics)
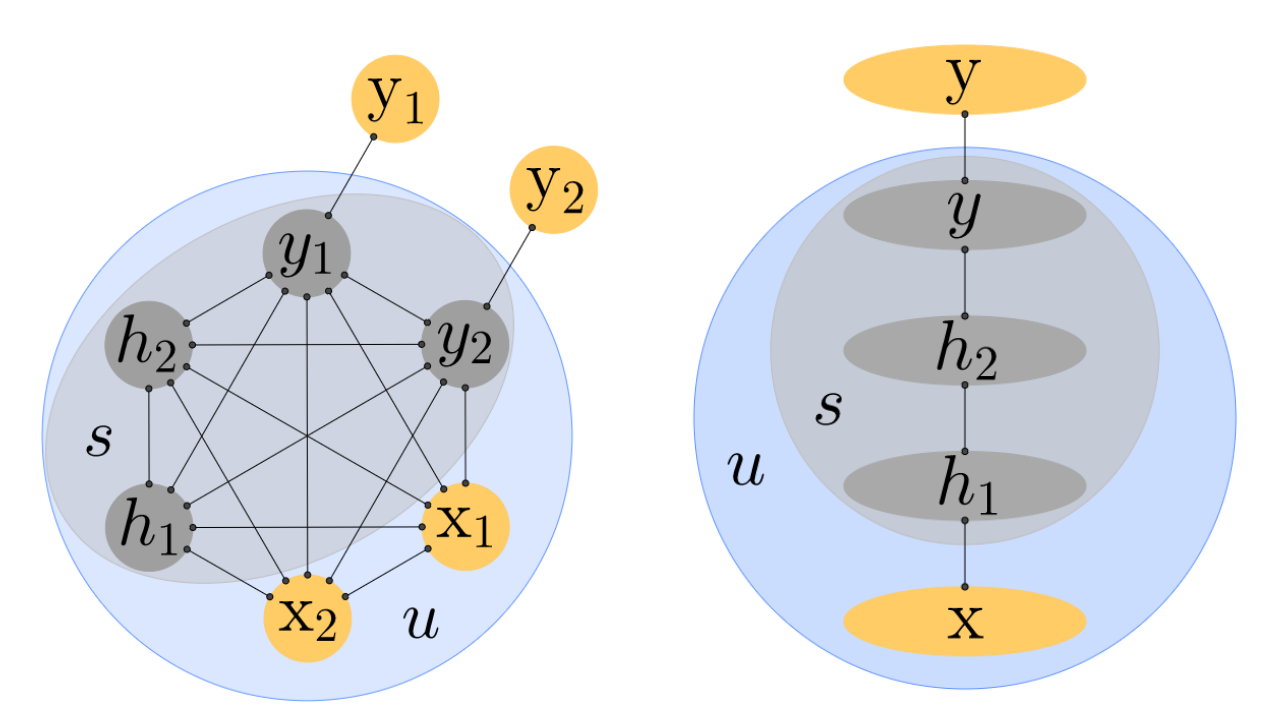
图 1: 左图:EqProp 适用于任何对称连接的架构。右图:在分层架构中,与 BP 的联系更为明显。
网络状态 $s = \{h, y\}$ 的演化遵循梯度下降动力学:
$$\frac{ds}{dt} = -\frac{\partial F}{\partial s} = -\frac{\partial E}{\partial s} - \beta \frac{\partial C}{\partial s}$$
这意味着系统会随时间推移降低总能量 $F$,直到达到固定点($\frac{ds}{dt} = 0$)。
* 内部力:$-\frac{\partial E}{\partial s_i} = \rho'(s_i) \left( \sum_{j \neq i} W_{ij} \rho(u_j) + b_i \right) - s_i$(类似于泄漏积分器模型)。
* 外部力:$-\beta \frac{\partial C}{\partial y_i} = \beta(y_i - y_i)$(仅作用于输出单元)。
2.3 两个阶段与误差反向传播
-
自由相 (Free Phase, $\beta=0$):
- 输入 $x$ 被钳制,$\beta=0$。
- 网络弛豫至 自由固定点 (Free Fixed Point) $u^0$。
- 此时输出 $y$ 是自由预测的结果。
-
弱钳制相 (Weakly Clamped Phase, $\beta > 0$):
- 引入微小的 $\beta > 0$。
- 输出单元受到指向目标 $y$ 的“推力”。
- 网络弛豫至新的 弱钳制固定点 (Weakly Clamped Fixed Point) $u^\beta$。
- 这个过程将输出层的扰动反向传播到隐藏层,编码了误差导数。
学习规则:
在 $\beta \to 0$ 的极限下,以下更新规则对应于目标函数 $J$ 的随机梯度下降:
$$\Delta W_{ij} \propto \frac{1}{\beta} \left( \rho(u_i^\beta)\rho(u_j^\beta) - \rho(u_i^0)\rho(u_j^0) \right)$$
2.4 与 STDP 的联系
该学习规则可以解释为一种特定形式的脉冲时序依赖可塑性 (STDP)。如果突触变化率满足 $\frac{dW_{ij}}{dt} \propto \rho(u_i) \frac{d\rho(u_j)}{dt}$,在对称权重下积分该变化,可以得到上述的 EqProp 更新规则。
3. 能量模型的机器学习框架 (A Machine Learning Framework)
本节将上述特定模型推广为通用的机器学习框架。
3.1 训练目标 (Training Objective)
对于给定的数据 $v$(包含输入和目标),我们关注固定点 $s_{\theta, v}^0$:
$$s_{\theta, \mathbf{v}}^{0} \in \underset{s}{\operatorname{arg\,min}} E(\theta, \mathbf{v}, s)$$
目标函数 $J$ 定义为固定点处的代价:
$$J(\theta, \mathbf{v}) := C\left(\theta, \mathbf{v}, s_{\theta, \mathbf{v}}^{0}\right)$$
训练目标是找到 $\theta$ 最小化 $J(\theta, \mathbf{v})$。
3.2 核心定理:梯度公式 (Theorem 1)
Theorem 1 (Deterministic version):
目标函数 $J$ 对参数 $\theta$ 的梯度由下式给出:
$$\frac{\partial J}{\partial \theta}(\theta, \mathbf{v}) = \lim_{\beta \to 0} \frac{1}{\beta} \left( \frac{\partial F}{\partial \theta} \left( \theta, \mathbf{v}, \beta, s_{\theta, \mathbf{v}}^{\beta} \right) - \frac{\partial F}{\partial \theta} \left( \theta, \mathbf{v}, 0, s_{\theta, \mathbf{v}}^{0} \right) \right)$$
或者等价地:
$$\frac{\partial J}{\partial \theta}(\theta, \mathbf{v}) = \frac{\partial C}{\partial \theta} \left( \theta, \mathbf{v}, s_{\theta, \mathbf{v}}^{0} \right) + \lim_{\beta \to 0} \frac{1}{\beta} \left( \frac{\partial E}{\partial \theta} \left( \theta, \mathbf{v}, s_{\theta, \mathbf{v}}^{\beta} \right) - \frac{\partial E}{\partial \theta} \left( \theta, \mathbf{v}, s_{\theta, \mathbf{v}}^{0} \right) \right)$$
这意味着梯度的计算只需要两个固定点的状态信息:$s^0$ (自由相) 和 $s^\beta$ (弱钳制相)。
Proposition 2:
函数 $\beta \mapsto C(\theta, \mathbf{v}, s_{\theta, \mathbf{v}}^{\beta})$ 在 $\beta=0$ 处的导数是非正的。这说明弱钳制相确实将状态推向了代价更低(误差更小)的方向。
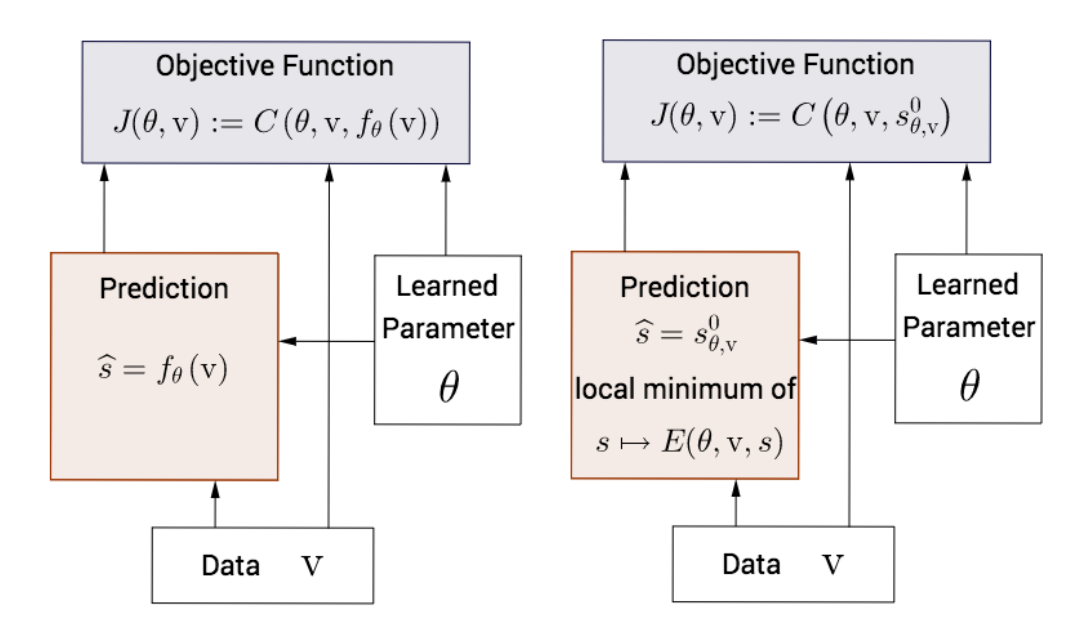
图 2: 传统深度学习(左)与 EqProp 框架(右)的对比。EqProp 中固定点是隐式定义的,梯度通过数值方法计算。
3.3 另一种视角
可以先定义总能量 $F$,然后导出其他量:
* $E(\theta, v, s) := F(\theta, v, 0, s)$
* $C(\theta, v, s) := \frac{\partial F}{\partial \beta}(\theta, v, 0, s)$
在这种视角下,$F$ 是描述模型与外界交互的核心对象。
4. 相关工作对比 (Related Work)
| 算法 | 第一阶段 | 第二阶段 | 备注 |
|---|---|---|---|
| Backpropagation | 前向传播 (Forward Pass) | 反向传播 (Backward Pass) | 需要专门的计算图和反向电路 |
| Equilibrium Prop | 自由相 (Free Phase) | 弱钳制相 (Weakly Clamped Phase) | 统一的神经计算,计算真梯度 |
| Contrastive Hebbian (CHL) | 自由相 (Free Phase) | 钳制相 (Clamped Phase) | 优化目标不同,可能存在模式不匹配问题 |
| Recurrent Backprop | 自由相 | Recurrent Backprop | 第二阶段需要线性化计算,生物学不合理 |
- 与 CHL 的区别:CHL 的第二阶段是完全钳制 ($\beta \to \infty$),而 EqProp 是弱钳制 ($\beta \to 0$)。CHL 优化的目标函数 $J_{CHL} = E(u^\infty) - E(u^0)$ 可能在不同模式下失效,而 EqProp 优化的是预测误差 $J = \frac{1}{2}\|y^0 - y\|^2$。
- 与 Boltzmann Machine 的区别:EqProp 计算的是梯度的无偏估计(在 $\beta \to 0$ 极限下),而 CD 算法计算的是有偏估计。
5. 实验结果 (Experimental Results)
在 MNIST 数据集上测试了 1, 2, 3 个隐藏层的全连接网络。
- 训练误差:均达到 0.00%。
- 泛化误差:2% - 3% 之间。
- 实现细节:
- 使用离散化的梯度下降来模拟连续动力学:$s_i \leftarrow 0 \lor (s_i - \epsilon \frac{\partial F}{\partial s_i}) \land 1$ (Hard Sigmoid 激活)。
- Persistent Particles:利用上一次的固定点初始化下一次的自由相,加速收敛。
- 随机 $\beta$ 符号:随机选择 $\beta$ 的正负有助于正则化。
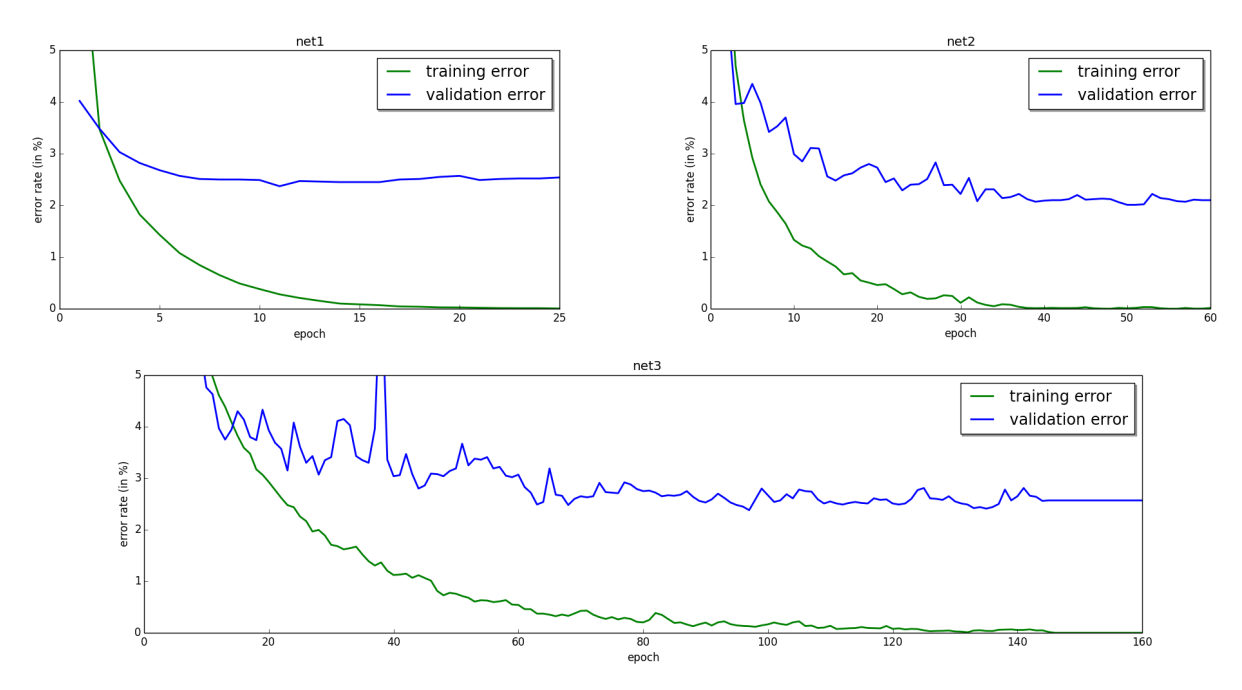
图 3: 不同层数网络的训练与验证误差曲线。
6. 讨论 (Discussion)
- 对称权重:EqProp 理论上要求权重对称 ($W_{ij} = W_{ji}$)。虽然生物学上不严格成立,但有研究表明自动编码器或去噪任务可能导致权重趋于对称。
- 弛豫时间:自由相的弛豫可能较慢。未来可以通过训练层间自动编码器来加速推断。
- 生物学意义:EqProp 提供了一种机制,使得类似 BP 的误差传播可以在不需要专门反向电路的情况下,通过单一的神经动力学实现。这为大脑如何实现高效学习提供了新的理论假设。
附录:梯度公式证明概要
Lemma 3: 对于满足 $\frac{\partial F}{\partial s}(\theta, \beta, s_\theta^\beta) = 0$ 的固定点 $s_\theta^\beta$,有:
$$\left( \frac{d}{d\theta} \frac{\partial F}{\partial \beta} \right)^T = \frac{d}{d\beta} \frac{\partial F}{\partial \theta}$$
利用此引理,结合 $J = \frac{\partial F}{\partial \beta}|_{\beta=0}$,即可推导出 Theorem 1 中的梯度公式。
这表明参数 $\theta$ 对“能量对 $\beta$ 的敏感度”(即代价函数)的梯度,等价于参数 $\beta$ 对“能量对 $\theta$ 的敏感度”的梯度。