Multi-scale Evolutionary Neural Architecture Search for Deep Spiking Neural Networks
深度脉冲神经网络的脑启发多尺度演化神经架构搜索
原文链接: http://arxiv.org/abs/2304.10749v5 作者: Wenxuan Pan, Feifei Zhao, Guobin Shen, Bing Han, Yi Zeng (中科院自动化所)
摘要 (Abstract)
脉冲神经网络(SNN)因其离散信号处理带来的能源效率以及整合多尺度生物可塑性的潜力而备受关注。然而,大多数 SNN 直接采用深度神经网络(DNN)的结构,很少针对 SNN 进行自动化的神经架构搜索(NAS)。
人脑具有微观(神经元)、介观(神经回路模体)和宏观(脑区连接)的多尺度拓扑结构,这是自然进化的产物。受此启发,本文提出了多尺度演化神经架构搜索(MSE-NAS): 1. 搜索空间:同时考虑微观、介观和宏观尺度的脑拓扑结构。 2. 演化对象:演化单个神经元操作、多个电路模体(Motifs)的自组织整合以及模体间的全局连接。 3. 评估方法:提出了一种脑启发的间接评估(BIE)函数,无需训练即可评估适应度,极大地减少了计算消耗。
实验表明,MSE-NAS 在静态数据集(CIFAR10/100)和神经形态数据集(CIFAR10-DVS, DVS128-Gesture)上均实现了 SOTA 性能,且具有极佳的迁移性、鲁棒性和能源效率。
I. 引言 (Introduction)
人脑经过数百万年的进化,形成了特定的神经回路和模块化区域结构,具备从微观神经元交互到宏观脑区协作的多尺度信息处理能力。 - 现状:SNN 研究多集中在训练算法(如代理梯度),架构设计多沿用 DNN(如 ResNet, VGG)。 - 问题:SNN 的累积-发放机制与 DNN 不同,直接迁移架构效率不高。现有的 SNN-NAS 研究缺乏对脑多尺度拓扑的深入借鉴,且评估成本高昂。 - 本文方案:MSE-NAS 模拟大脑的微观、介观、宏观拓扑演化,并利用脑神经活动稳定性原理设计无训练评估指标(BIE)。
II. 相关工作 (Related Work)
- 演化神经架构搜索 (ENAS):相比梯度和强化学习方法,ENAS 通过种群迭代更容易获得全局最优解。
- 搜索空间:从基于 Cell/Block 的搜索发展而来。本文首次直接借鉴大脑演化的多尺度神经拓扑。
- SNN 的 NAS:现有工作(如 AutoSNN)仍依赖 DNN 模块。
- 适应度评估:传统方法需训练模型(耗时)。本文提出了针对 SNN 的高效间接评估方法。
III. 深度 SNN 的多尺度演化神经架构搜索 (Method)
本节详细介绍 MSE-NAS 的核心机制,包括基础组件、多尺度编码空间及脑启发间接评估(BIE)。
A. 脉冲神经网络基础 (SNN Foundations)
1. Leaky Integrate-and-Fire (LIF) 神经元
神经元是微观计算单元,其膜电位 $V_m(t)$ 的更新公式如下:
$$ \tau_m \frac{dV_m(t)}{dt} = I(t) - V_m(t) \tag{1} $$
其中 $I(t)$ 是外部输入,$\tau_m$ 是时间常数。当 $V_m(t)$ 超过阈值 $V_{th}=0.5$ 时发放脉冲。
2. 神经微电路 (Neural Microcircuits / Motifs)
受生物脑启发,本文定义了 5 种常见的神经回路模体作为介观结构的基础,如图 1 所示:
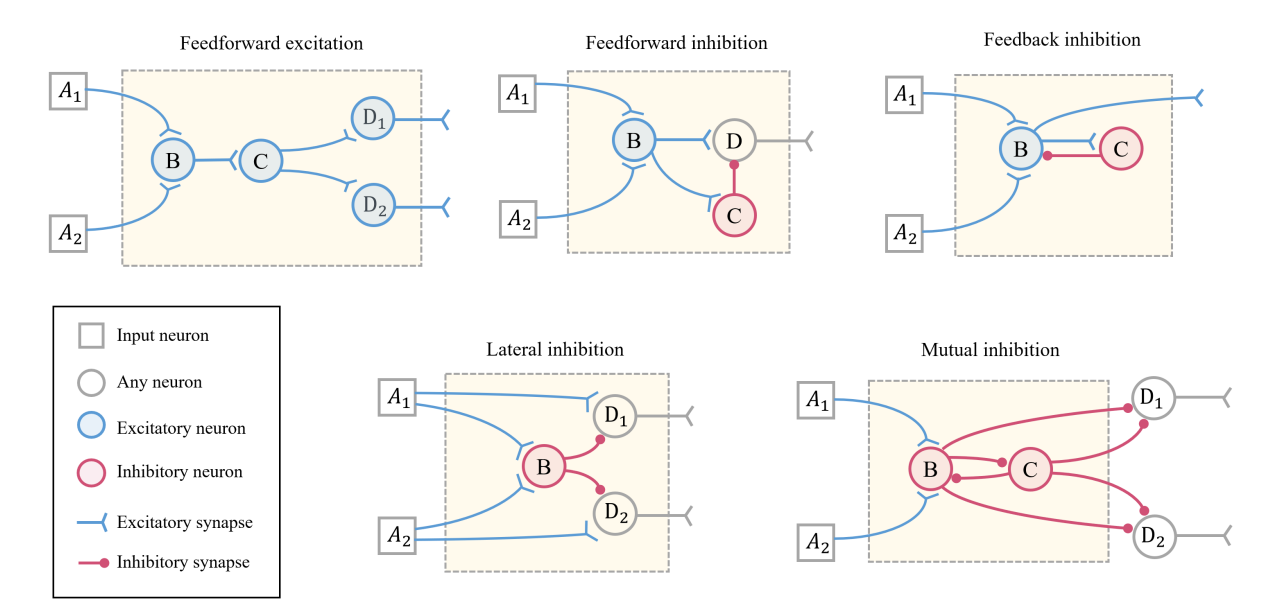
- 前馈兴奋 (FE):收敛兴奋输入,增强信号整合。
- 前馈抑制 (FI):通过抑制性神经元调节兴奋信号的幅度。
- 反馈抑制 (FbI):输出信号反馈回抑制神经元,增强信噪比。
- 侧向抑制 (LI):放大差异,锐化感知(常见于视觉/听觉)。
- 相互抑制 (MI):神经元间互相抑制,用于节律生成。
B. 多尺度演化编码 (Multi-scale Encoding)
MSE-NAS 将搜索空间分解为微观、介观和宏观三个尺度,编码为基因型 $[X, M, G]$。
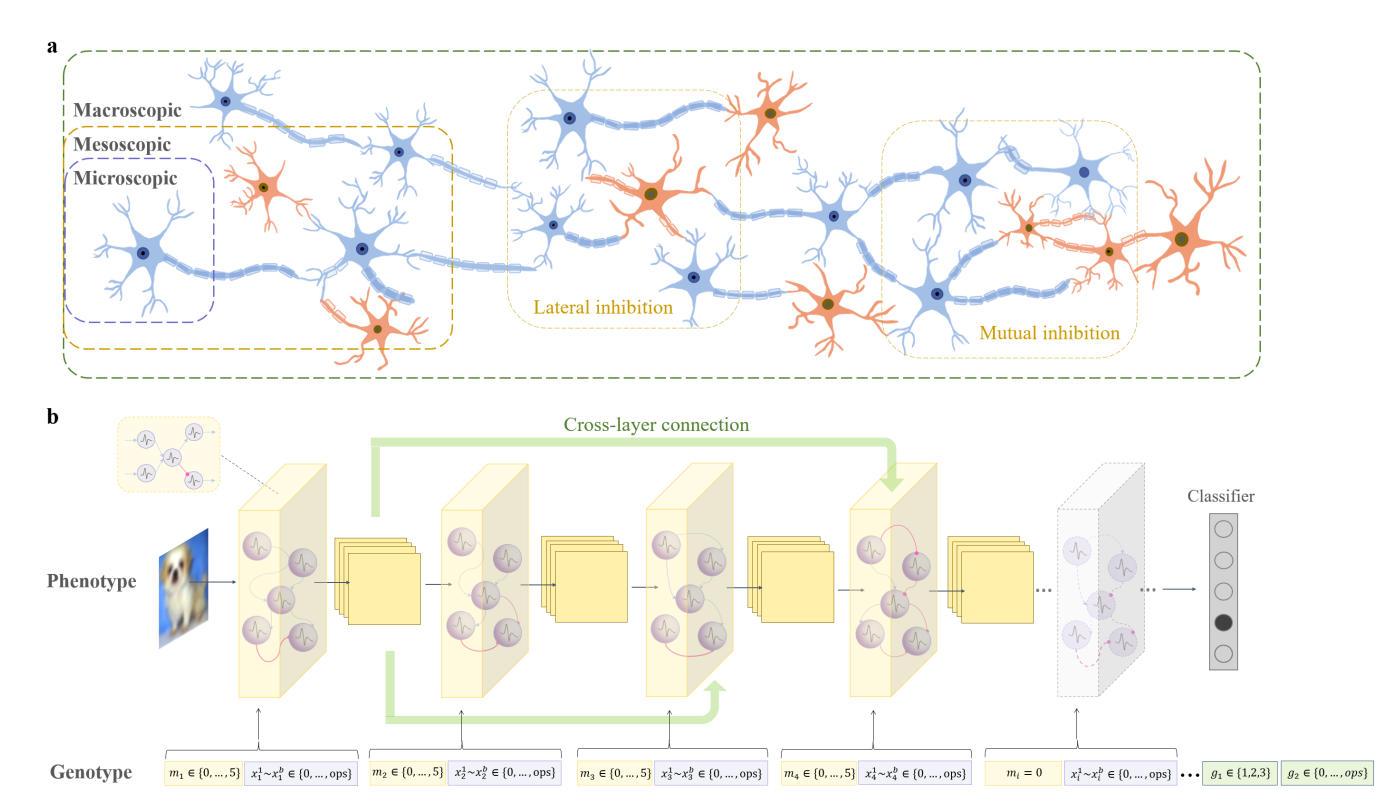
基因型定义: 假设网络最大层数为 $l$,每个层由 $b$ 个基因编码微观操作。基因型表示为:
$$ [X, M, G] = [(m_1, x_1^1, ... x_1^b), ..., (m_l, x_l^1, ... x_l^b), g_1, g_2] \tag{2} $$
各部分数学含义如下(详见 Table I):
-
微观尺度 (Micro, $X$):
- $x_i^k \in \{0, 1, 2\}$:定义模体内部神经元的具体操作。
- 取值:0 (Empty), 1 (3x3 Conv), 2 (5x5 Conv)。
-
介观尺度 (Meso, $M$):
- $m_i \in \{0, 1, 2, 3, 4, 5\}$:定义第 $i$ 层的神经微电路类型。
- 对应关系:0 (空层), 1 (FE), 2 (FI), 3 (FbI), 4 (LI), 5 (MI)。
- $m_i$ 的非零数量决定了网络的实际深度。
-
宏观尺度 (Macro, $G$):
- $g_1 \in \{1, 2, 3\}$:定义层间连接模式(跨层连接)。
- 1: 仅连接上一层(普通前馈)。
- 2: 同时接收前 2 层输入。
- 3: 同时接收前 3 层输入。
- $g_2 \in \{1, 2\}$:定义跨层连接的卷积核大小(3x3 或 5x5)。
- $g_1 \in \{1, 2, 3\}$:定义层间连接模式(跨层连接)。
演化过程:采用锦标赛选择,两点交叉(仅在 Meso/Macro 层级),位翻转变异(全尺度)。
C. 脑启发间接评估 (Brain-inspired Indirect Evaluation, BIE)
为了避免昂贵的训练过程,作者基于神经活动稳定性假设设计了 BIE:一个好的架构在面对不同输入时,其神经元群体的整体发放模式应保持某种内在的稳定性(Homeostasis)。
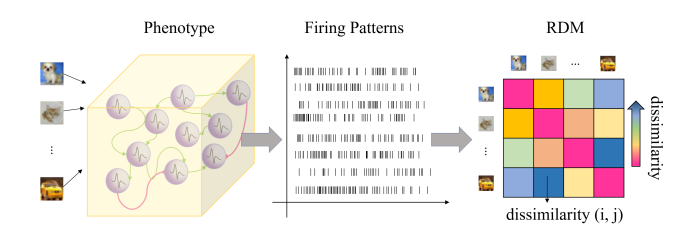
1. 发放模式 (Firing Pattern) 对于一个个体 $Individual_i$,输入样本后,记录 $n_{neu}$ 个神经元在 $T$ 时间步内的发放总数,形成向量 $P_i$:
$$ P_i = \left(\begin{array}{ccc} \sum_0^T p_1^t & \cdots & \sum_0^T p_{n_{neu}}^t \end{array}\right) \tag{3} $$
其中 $p_z^t \in \{0, 1\}$ 表示神经元 $z$ 在 $t$ 时刻是否发放。
2. 差异矩阵 (Difference Matrix) 输入一批样本(Batch size = $j$),计算同一个体对不同样本响应的差异。距离度量采用曼哈顿距离 $d(u,v)$:
$$ BIE_{i} = \begin{pmatrix} d(P_{i}^{1}, P_{i}^{1}) & \cdots & d(P_{i}^{1}, P_{i}^{j}) \\ \vdots & \ddots & \vdots \\ d(P_{i}^{j}, P_{i}^{1}) & \cdots & d(P_{i}^{j}, P_{i}^{j}) \end{pmatrix} \tag{5} $$
3. 优化目标 演化的目标是最小化同一网络对不同样本响应的差异(即追求架构层面的活动稳定性)。BIE 适应度函数定义为:
$$ \underset{[X_{i},M_{i},G_{i}]}{\arg\min} \frac{1}{s} \sum_{j=1}^{s} BIE_{i}^{j} \tag{7} $$
注:相比于直接追求高准确率(通常需要最大化类间方差),这里利用未经训练的初始化网络的稳定性作为先验,筛选出鲁棒的架构。
IV. 实验与分析 (Experiments)
A. 性能表现 (Results)
MSE-NAS 在多个数据集上均取得了 SOTA 效果,优于人工设计的 SNN 和其他 NAS 方法。
| 数据集 | 方法 | 准确率 (Accuracy) | 优势 |
|---|---|---|---|
| CIFAR10 | MSE-NAS (STBP) | 96.58% | 比 ResNet-19 (TET) 高 2.14%,比 AutoSNN 高 3.43% |
| CIFAR100 | MSE-NAS (STBP) | 80.56% | 比其他 NAS 方法高 7%~11% |
| CIFAR10-DVS | MSE-NAS | 84.0% | 显著优于 VGGSNN (TET) |
| DVS128-Gesture | MSE-NAS | 98.10% | SOTA |
B. 消融实验 (Ablation Study)
- 介观尺度:混合模体(MSE-NAS)的效果优于单一模体(如全 FE 或全 LI)。
- E/I 平衡发现:如图 5 所示,性能最好的个体倾向于拥有兴奋-抑制平衡的模体组合,而性能差的个体往往抑制性模体过多。
- 宏观尺度:跨层连接(Macro evolution)相比单纯的前馈结构,在所有数据集上提升了 0.9%~2.2% 的准确率。
C. BIE 的效率与有效性
- 效率:在 CIFAR10 上,BIE 评估仅需 0.83 GPU Hours,比直接训练评估(50 GPU Hours)快 60倍。
- 收敛性:如图 6 所示,随着演化代数增加,种群的平均适应度(BIE 分数)和最终准确率呈现正相关。
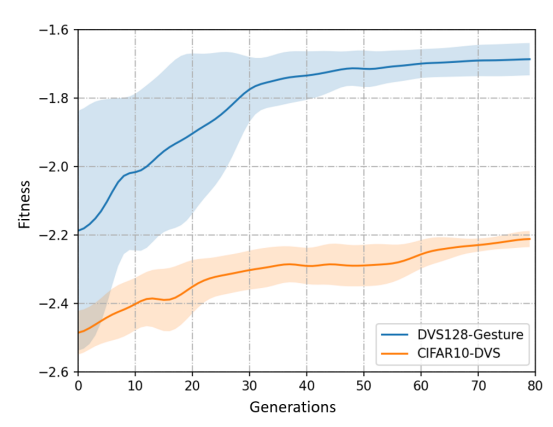
D. 迁移性与鲁棒性
- 迁移性:在一个数据集(如 DVS Gesture)上演化出的架构,直接作为初始种群迁移到另一数据集(如 CIFAR10-DVS),能保持高性能起点并快速收敛(图 7)。
- 抗噪性:在添加高斯噪声的情况下,MSE-NAS 的性能下降幅度远小于其他方法(如 TIC),展现出极强的鲁棒性。
- 能耗:MSE-NAS 以更少的脉冲数(Spike count)实现了更高的准确率。例如在 CIFAR10 上,仅需 177.6K 脉冲,约为人工设计网络能耗的 1/3。
V. 结论 (Conclusion)
本文提出的 MSE-NAS 成功将生物脑的多尺度拓扑演化机制引入 SNN 架构搜索。 1. 多尺度融合:微观神经元、介观模体、宏观连接的协同演化显著提升了 SNN 的表达能力。 2. BIE 评估:基于稳定性的无训练评估方法解决了 NAS 耗时痛点,并偏好鲁棒性强的架构。 3. 生物可解释性:演化结果自发涌现出兴奋-抑制平衡(E/I Balance)特性,验证了类脑结构的优越性。