World Models
作者: David Ha, Jürgen Schmidhuber (Google Brain, IDSIA) 论文链接: http://arxiv.org/abs/1803.10122v4 互动版本: https://worldmodels.github.io
1. 引言 (Introduction)
人类根据自己有限的感官所感知到的信息,在头脑中建立了一个世界的心理模型(Mental Model)。我们所做的决定和行动都是基于这个内部模型。正如系统动力学之父 Jay Wright Forrester 所说,我们头脑中的世界形象只是一个模型,我们只选择了概念和它们之间的关系来代表真实系统。
我们的大脑通过学习空间和时间上的抽象表示来处理海量信息。更重要的是,我们的感知在很大程度上受大脑对未来预测的支配。例如,棒球击球手在毫秒间做出击球决定,靠的是本能地预测球的轨迹,而不是有意识地规划未来。

在强化学习(RL)中,智能体(Agent)也能从良好的状态表示和未来预测模型中获益。虽然大型循环神经网络(RNN)具有强大的表现力,但通过无模型(Model-Free)RL 训练它们非常困难,因为面临信用分配(Credit Assignment)问题。
本文提出了一种新的方法:将智能体分为一个大的世界模型(World Model)和一个小的控制器(Controller)。 1. 首先以无监督的方式训练一个大型神经网络来学习世界的模型(压缩的空间和时间表示)。 2. 然后训练一个简单的、紧凑的控制器模型,使用世界模型提取的特征来执行任务。 3. 甚至可以完全在世界模型生成的“梦境”(幻觉)中训练智能体,然后将其策略迁移回真实环境。
2. 智能体模型 (Agent Model)
该模型受到人类认知系统的启发,由三个组件组成:视觉(V)、记忆(M)和控制器(C)。
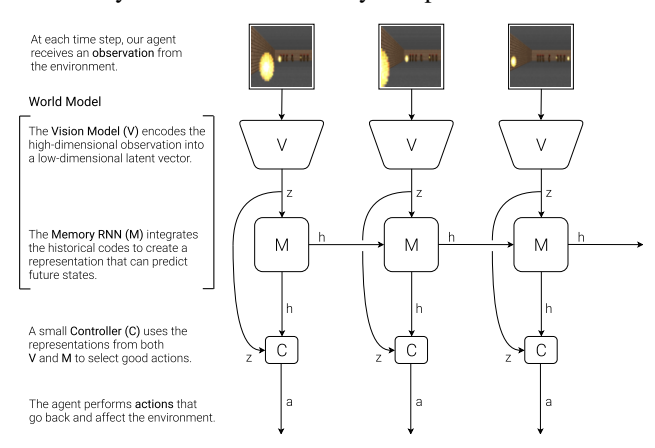
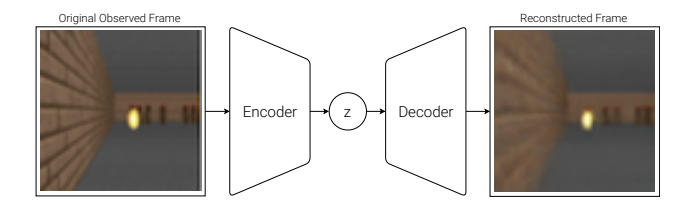
2.1 视觉模型 V (VAE)
- 作用:压缩高维输入(如 2D 图像帧)为低维的潜变量(Latent Vector)$z$。
- 实现:使用变分自编码器(Variational Autoencoder, VAE)。
- 目的:学习每一帧的抽象、压缩表示。
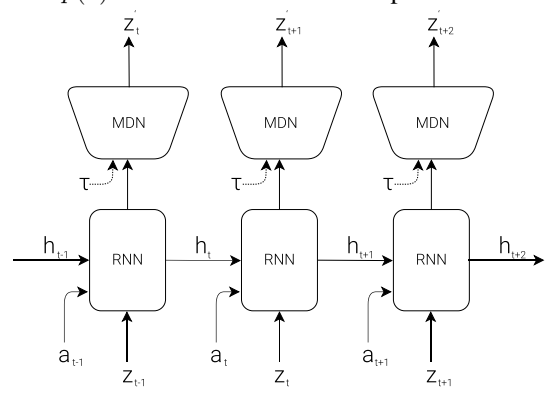
2.2 记忆模型 M (MDN-RNN)
- 作用:预测未来。基于历史信息预测 V 模型未来可能产生的潜变量 $z$。
- 实现:结合了混合密度网络(Mixture Density Network, MDN)的 RNN (LSTM)。
- 输出:不是输出确定性的预测,而是输出下一个潜变量 $z_{t+1}$ 的概率密度函数 $P(z_{t+1} | a_t, z_t, h_t)$(建模为高斯混合分布)。
- 温度参数 $\tau$:在采样时,可以调整温度 $\tau$ 来控制模型的不确定性/随机性。
2.3 控制器模型 C (Controller)
- 作用:根据 V 和 M 的表示来决定动作,以最大化累积奖励。
- 实现:一个简单的单层线性模型。
- 公式:$a_t = W_c [z_t, h_t] + b_c$。输入是当前帧的潜变量 $z_t$ 和 RNN 的隐藏状态 $h_t$ 的拼接。
- 训练:由于 C 的参数非常少(最小化设计),可以使用进化策略(CMA-ES)进行高效训练,避免了反向传播中的梯度问题。
2.4 整体交互流程
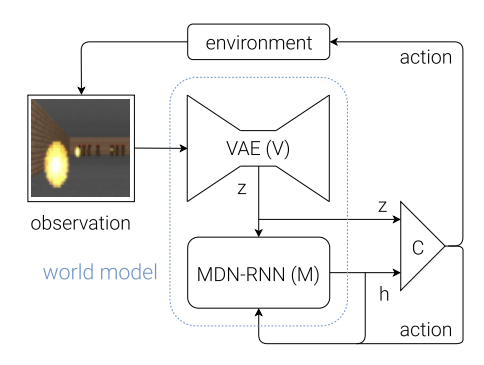
- 环境提供原始观测。
- V 将观测编码为 $z_t$。
- C 根据 $z_t$ 和 M 的隐藏状态 $h_t$ 输出动作 $a_t$。
- 环境执行 $a_t$,返回奖励和新状态。
- M 根据 $z_t$ 和 $a_t$ 更新其隐藏状态到 $h_{t+1}$,用于下一步预测。
3. 赛车实验 (Car Racing Experiment)
任务环境是 OpenAI Gym 的 CarRacing-v0,是从像素输入的俯视赛车游戏。
3.1 训练过程
- 收集数据:使用随机策略运行 10,000 次,记录观察到的图像和动作。
- 训练 V (VAE):训练 VAE 将图像压缩为 $z \in \mathbb{R}^{32}$。
- 训练 M (MDN-RNN):使用 V 处理后的数据,训练 RNN 预测 $P(z_{t+1} | a_t, z_t, h_t)$。
- 训练 C (Controller):定义线性控制器,使用 CMA-ES 算法优化参数 $W_c$,最大化预期累积奖励。
3.2 实验结果
- 仅使用 V 的控制器:如果控制器只能看到 $z_t$(看不到 $h_t$),驾驶不稳定,容易在急转弯处失误。
- 完整世界模型 (V + M):给予控制器 $z_t$ 和 $h_t$(包含未来的预测信息)。驾驶非常稳定,能够像职业赛车手一样本能地预测弯道。
- SOTA 表现:该方法达到了 906 ± 21 的平均分,解决了该任务(之前的方法如 A3C 只有 ~600 分)。这是已知的第一个在该任务上达到“解决”标准的方法。
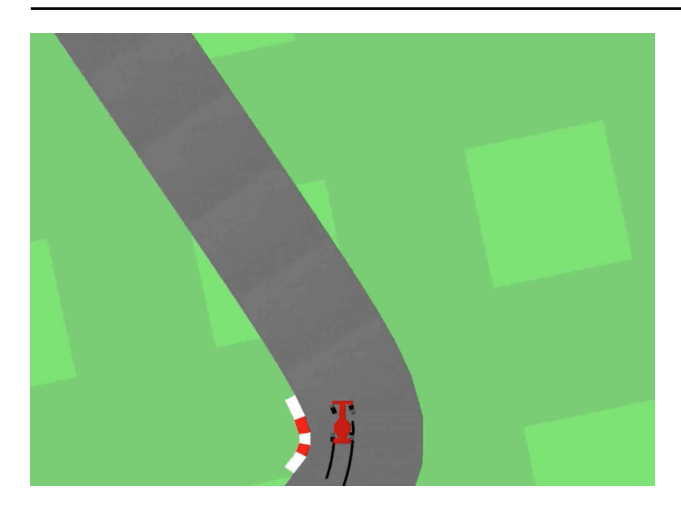
3.3 赛车梦境 (Car Racing Dreams)
由于 M 模型可以预测未来,我们可以让智能体在 M 生成的“幻觉”中驾驶,即不通过真实环境,而是由 M 预测下一个 $z_{t+1}$ 作为输入。

4. VizDoom 实验:在梦中学习 (Learning Inside of a Dream)
在这个实验中,作者探索了完全在世界模型的幻觉中训练智能体,然后将学到的策略迁移回真实世界。
4.1 任务:VizDoom Take Cover
智能体需要移动以躲避怪物发射的火球。目的是尽可能长时间存活。
4.2 过程
- 收集随机策略数据。
- 训练 V (VAE) 压缩帧。
- 训练 M (MDN-RNN) 预测下一帧 $z_{t+1}$ 以及智能体是否死亡 (done)。
- 构建虚拟环境:使用 M 构建一个完全基于潜变量空间的 OpenAI Gym 接口环境。
- 在梦中训练:在虚拟环境中即使用 CMA-ES 训练控制器 C。
- 迁移:将训练好的 C 部署到真实的 VizDoom 环境中。
4.3 结果
- 智能体在虚拟环境中学会了躲避火球(得分 ~900)。
- 迁移效果:将策略放回真实环境,得分高达 ~1100(任务要求 750),甚至超过了在虚拟环境中的表现。
- 这证明了智能体可以从一个近似的、甚至不完美的模拟世界中学习到可迁移的技能。
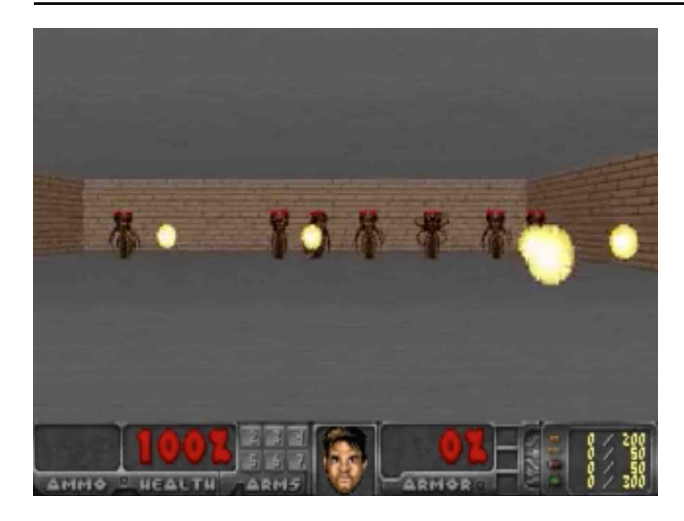
4.4 欺骗世界模型 (Cheating the World Model)
在梦中训练的一个风险是,智能体可能会发现世界模型的漏洞(Adversarial Policy)。 * 例如,智能体发现某种特殊的移动方式可以让 M 模型预测“怪物不发射火球”,从而在梦中“作弊”存活。 * 解决方案:增加 M 模型的温度参数 $\tau$。通过增加环境的不确定性(随机性),使环境变得更不可预测和困难,迫使智能体学习更稳健的策略,而不是利用模型的确定性漏洞。 * 实验显示,适当增加 $\tau$(如 $\tau=1.15$)训练出的策略在真实世界中泛化能力更强。
 (上图展示了智能体通过特定移动让火球在梦境中神奇消失的作弊行为)
(上图展示了智能体通过特定移动让火球在梦境中神奇消失的作弊行为)
5. 讨论 (Discussion)
- 计算优势:在潜变量空间(Latent Space)的梦境中训练比在真实像素环境中渲染和物理计算要快得多、成本低得多。
- 迭代训练 (Iterative Training):对于更复杂的任务,可以采用迭代过程:探索环境 -> 收集数据 -> 改进世界模型 -> 改进控制器 -> 再次探索。
- 好奇心与内在动机:可以通过奖励 M 模型预测误差大的状态,来鼓励智能体探索未知区域,从而改进世界模型。
- 海马体回放 (Hippocampal Replay):这种在梦中(模型中)训练和回放经历的机制,与神经科学中海马体在睡眠或休息时回放记忆以巩固学习的机制有相似之处。
6. 结论 (Conclusion)
本文展示了通过构建生成式神经网络世界模型来解决强化学习问题是可行的。 * World Models 能够以无监督方式快速训练,学习环境的压缩时空表示。 * V+M+C 架构 使得控制器可以非常简单(仅数百个参数),从而可以使用进化算法高效优化。 * 在梦中学习:首次展示了可以在世界模型生成的幻觉中完全训练一个智能体,并成功将其迁移到真实环境,且性能优异。
这一方法为训练大规模神经网络来解决强化学习任务提供了一条无需面对传统梯度信用分配难题的新路径。
附录:模型参数量
| 模型 | VizDoom 参数量 | CarRacing 参数量 |
|---|---|---|
| VAE (V) | ~4.4M | ~4.3M |
| MDN-RNN (M) | ~1.7M | ~0.4M |
| Controller (C) | 1088 | 867 |
可以看到,绝大部分参数和复杂性都在世界模型(V和M)中,而负责决策的控制器 C 极小。