Evolving Neural Networks through Augmenting Topologies (NEAT) 论文笔记
作者: Kenneth O. Stanley & Risto Miikkulainen (University of Texas at Austin)
核心贡献: 提出了一种名为 NEAT (NeuroEvolution of Augmenting Topologies) 的神经进化方法,通过同时进化神经网络的拓扑结构 (Topology) 和权重 (Weights),实现了比固定拓扑方法更高效的学习。
1. 简介 (Introduction)
神经进化 (Neuroevolution, NE) 是利用遗传算法 (GA) 进化神经网络的方法。传统的 NE 方法通常预先设定一个固定的拓扑结构(例如全连接的前馈网络),然后仅进化连接权重。
固定拓扑的局限性:
1. 结构难以预设: 对于复杂问题,很难预先知道需要多少个隐藏层或隐藏节点。
2. 搜索空间未优化: 即使全连接网络理论上可以近似任何函数,但如果可以通过进化找到更精简的拓扑结构,搜索空间的维度会大大降低,从而加速学习。
NEAT 的核心主张:
如果方法得当,同时进化拓扑结构和权重可以显著提升性能。NEAT 通过以下三个关键技术实现这一点:
1. 历史标记 (Historical Markings): 解决不同拓扑结构之间的交叉 (Crossover) 问题。
2. 物种形成 (Speciation): 保护新的结构创新 (Structural Innovation) 免受过早淘汰。
3. 从最小结构开始增量生长 (Incremental Growth from Minimal Structure): 始终保持搜索空间的最小化。
2. 核心挑战与背景 (Background & Challenges)
在设计 TWEANN (Topology and Weight Evolving Artificial Neural Networks) 系统时,面临几个主要难题:
2.1 竞争约定问题 (Competing Conventions Problem)
也称为排列问题 (Permutations Problem)。对于同一个神经网络功能解决方案,可能存在多种不同的基因表达方式(例如隐藏节点的排列顺序不同)。
如果两个父代网络功能相似但编码不同,直接交叉 (Crossover) 往往会产生功能受损的后代。
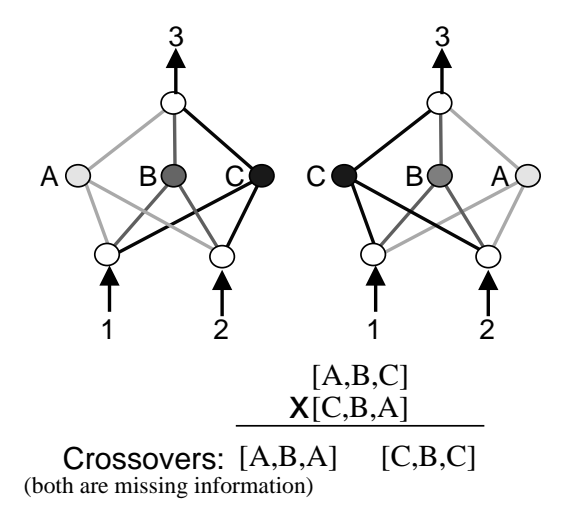
图 1: 竞争约定问题示例。两个网络计算相同的函数,但隐藏节点顺序不同([A,B,C] vs [C,B,A])。交叉后丢失了关键信息。
2.2 保护创新 (Protecting Innovation)
通过变异添加新的结构(如新节点或连接)通常会暂时降低网络的适应度(Fitness),因为新结构的权重尚未优化。在标准的优胜劣汰进化中,这些有潜力的创新往往在优化之前就被淘汰了。
2.3 初始种群 (Initial Populations)
许多系统从随机拓扑开始,但这引入了大量不必要的参数,且可能产生不可行的网络。NEAT 主张从最小结构开始。
3. NEAT 方法论 (Methodology)
NEAT 的设计精妙地解决了上述问题。
3.1 基因编码 (Genetic Encoding)
NEAT 采用直接编码。基因组 (Genome) 是线性的,包含两部分:
1. 节点基因 (Node Genes): 定义输入、隐藏和输出节点。
2. 连接基因 (Connection Genes): 定义节点间的连接。
每个连接基因包含以下信息:
* In-Node (输入节点 ID)
* Out-Node (输出节点 ID)
* Weight (权重)
* Enable Bit (启用/禁用位)
* Innovation Number (创新编号): 关键字段,用于历史追踪。
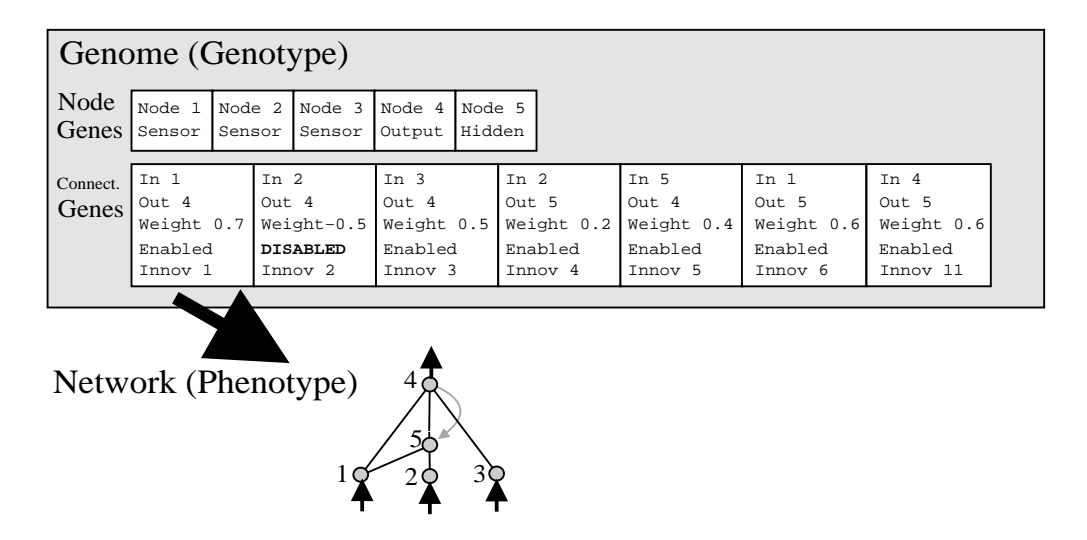
图 2: 基因型到表现型的映射。注意基因 2 被禁用 (Disabled),因此对应的连接在表现型中不存在。
3.2 结构变异 (Structural Mutation)
NEAT 有两种主要的结构变异方式:
1. 添加连接 (Add Connection): 在两个先前未连接的节点间添加新连接(随机权重)。
2. 添加节点 (Add Node): 分裂现有的连接。
* 例如:在节点 A 和 B 的连接中间插入新节点 C。
* 操作:禁用 A->B 的连接。添加 A->C(权重设为1)和 C->B(权重设为原 A->B 的权重)。
* 目的: 这种特殊的权重初始化使得新网络在初始时的行为与原网络几乎一致,减少了新结构带来的适应度震荡。
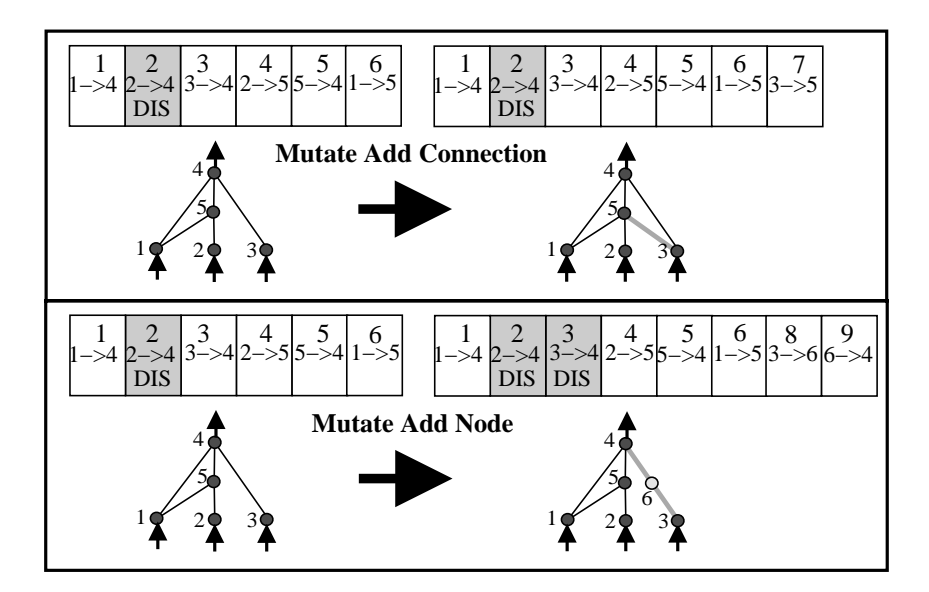
图 3: 两种结构变异。上方数字是创新编号。注意添加节点时,原连接被禁用,新生成的两个连接获得了新的创新编号。
3.3 历史标记与创新编号 (Historical Markings)
核心机制: 每当通过变异产生一个新的基因(新连接或新节点)时,系统会分配一个全局唯一的创新编号 (Global Innovation Number)。
- 原理: 如果两个基因具有相同的创新编号,说明它们来源于同一个祖先变异,因此它们代表相同的结构(同源)。
- 应用: 在交叉时,系统不需要进行昂贵的图匹配分析,只需对比创新编号即可对齐基因。
举例说明:
假设当前全局创新编号是 10。
- 变异 A: 在节点 1 和 4 之间加连接 -> 创新编号 11。
- 变异 B: 在节点 2 和 5 之间加连接 -> 创新编号 12。
无论这两个变异发生在哪个个体身上,只要系统中发生了特定的结构改变(记录在全局历史表中),就会被分配特定的编号。如果是同一代中两个不同个体独立发生了完全相同的突变(例如都连了 1->4),它们会被分配相同的创新编号,以避免编号爆炸。
3.4 交叉 (Crossover)
利用创新编号,交叉变得简单线性:
1. 匹配基因 (Matching Genes): 两个父代中具有相同创新编号的基因。随机继承。
2. 不相交基因 (Disjoint Genes): 创新编号在另一方编号范围内但不存在的基因。
3. 过量基因 (Excess Genes): 创新编号超出另一方编号范围的基因。
规则: 不相交和过量基因(代表结构差异)通常从适应度更高的父代继承。如果适应度相同,则随机继承。
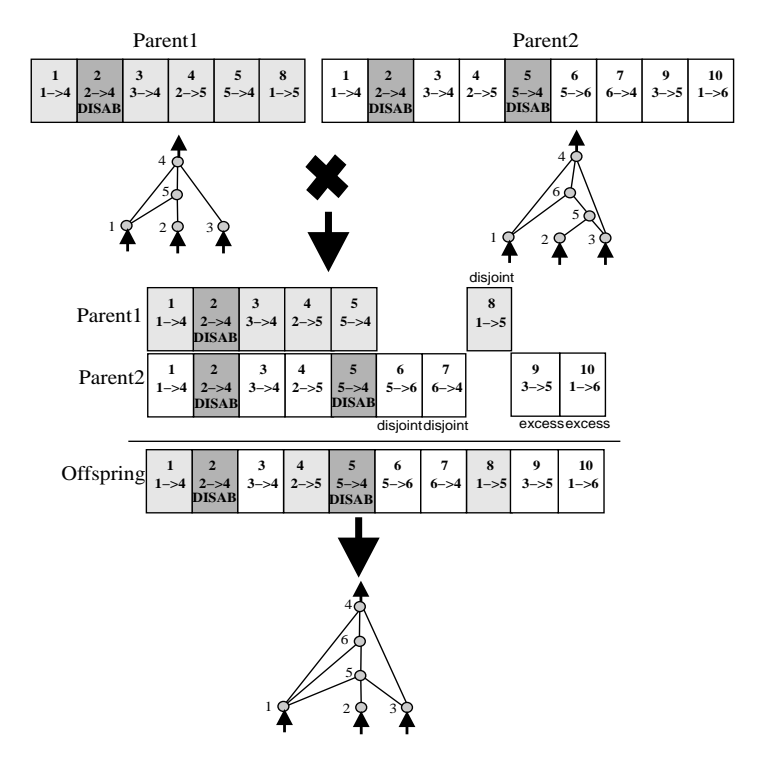
图 4: 基于创新编号的基因对齐。无需复杂的图分析,直接通过数字对齐。
3.5 通过物种形成保护创新 (Speciation)
为了防止新产生的(尚未优化的)复杂结构被过早淘汰,NEAT 将种群划分为不同的物种 (Species)。个体主要与同物种内的成员竞争。
3.5.1 兼容性距离 (Compatibility Distance)
如何决定两个网络是否属于同一物种?利用基因组差异计算距离 $\delta$:
$$ \delta = \frac{c_1 E}{N} + \frac{c_2 D}{N} + c_3 \cdot \overline{W} $$
- $E$: 过量基因 (Excess) 的数量。
- $D$: 不相交基因 (Disjoint) 的数量。
- $\overline{W}$: 匹配基因的平均权重差异。
- $N$: 较长基因组的基因总数(归一化因子)。
- $c_1, c_2, c_3$: 调整系数。
如果 $\delta < \delta_t$ (阈值),则认为属于同一物种。
3.5.2 显式适应度共享 (Explicit Fitness Sharing)
为了防止某个物种通过大量复制占据整个种群,NEAT 使用适应度共享。个体 $i$ 的调整后适应度 $f'_i$ 为:
$$ f_i' = \frac{f_i}{\sum_{j=1}^n \operatorname{sh}(\delta(i,j))} $$
其中分母实际上就是该个体所属物种的成员数量(因为对于同物种 $\operatorname{sh}=1$,不同物种 $\operatorname{sh}=0$)。
这意味着:物种越大,成员的平均适应度惩罚越重。这迫使种群在不同物种间保持多样性,保护了规模较小的新物种。
3.6 从最小结构增量生长 (Minimal Structure)
NEAT 的进化从没有隐藏节点的均匀种群开始(只有输入直接连到输出)。
* 优势: 始终从最低维度的搜索空间开始优化。只有在能够提升适应度时,进化才会推向更复杂的结构。
* 这与传统 TWEANN 从随机复杂结构开始形成鲜明对比。
4. 性能评估 (Performance Evaluations)
4.1 异或问题 (XOR)
- 任务: 解决非线性可分的 XOR 问题。
- 结果: NEAT 100% 成功,平均 32 代找到解。生成的网络非常精简(平均 2.35 个隐藏节点)。
- 验证: 证明 NEAT 能够自动进化出必要的隐藏层结构。

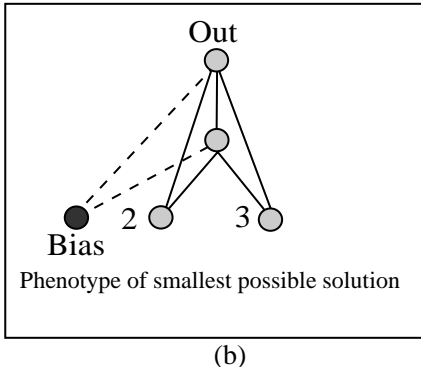
图 5: (a) 初始的无隐藏层网络。(b) 进化出的最优解。
4.2 双倒立摆平衡 (Double Pole Balancing)
这是更具挑战性的控制基准任务。
1. 带速度信息 (DPV): NEAT 所需评估次数最少,且网络结构最简(0-4个隐藏节点,而对比方法通常固定用10个)。
2. 不带速度信息 (DPNV): 非马尔可夫任务,必须进化出循环连接 (Recurrent connections) 来拥有记忆。
* 结果: NEAT 比之前的最优方法 (ESP) 快 5 倍,比 Cellular Encoding 快 25 倍。
* NEAT 能够发现极其精简的巧妙解法。
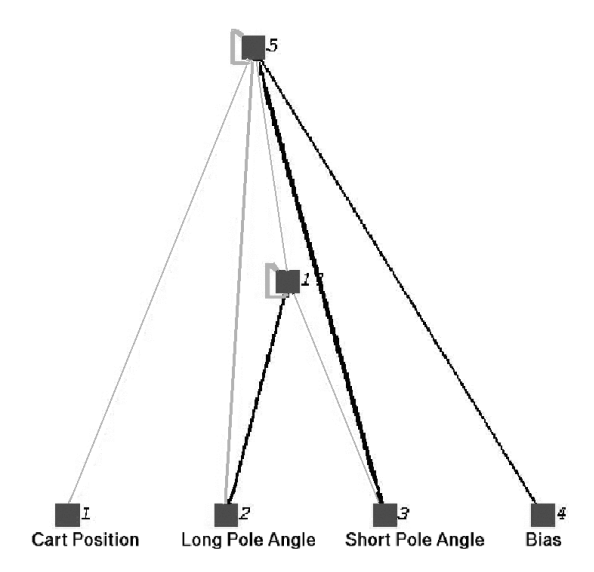
图 8: NEAT 在 DPNV 任务中发现的一个巧妙解法。利用一个循环连接的隐藏节点来判断摆的相对运动趋势,无需显式计算速度。
5. 分析与消融研究 (Analysis & Ablations)
为了证明 NEAT 各组件的必要性,作者进行了消融实验 (Ablation Studies)。
| 方法 | 结果 (平均评估次数) | 失败率 | 结论 |
|---|---|---|---|
| Full NEAT | 3,600 | 0% | 最优性能 |
| 无交叉 (Nonmating) | 5,557 | 0% | 交叉是有益的 |
| 初始随机种群 (Initial Random) | 23,033 | 5% | 从最小结构开始至关重要 |
| 无物种形成 (Nonspeciated) | 25,600 | 25% | 物种形成对保护多样性很关键 |
| 无生长 (No-Growth/Fixed) | 30,239 | 80% | 进化拓扑结构是核心优势 |
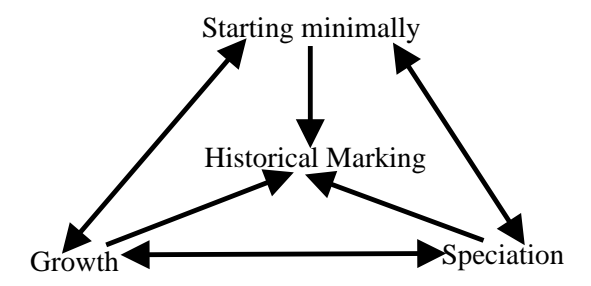
图 6: NEAT 组件间的依赖关系。所有组件协同工作,缺一不可。
物种可视化
可视化显示,随着进化的进行,新物种不断产生并尝试突破。旧物种如果停滞不前会灭绝。创新(如新的连接方式)确实导致了新物种的繁荣。

图 7: 进化物种图谱。横轴是物种大小,纵轴是代数。可以看到物种的兴衰更替。
6. 讨论与结论 (Discussion & Conclusion)
NEAT 的成功不仅仅在于优化权重,更在于它可以同时优化和复杂化 (Complexify) 解决方案。
* 连续协同进化 (Continual Coevolution): NEAT 允许策略不断通过增加结构变得更复杂,从而打破协同进化的循环僵局,产生真正的高级策略。
* 类比自然: NEAT 强化了人工进化与生物进化的类比——从简单单细胞生物逐渐进化为复杂生物。
总结: NEAT 通过历史标记解决了拓扑交叉难题,通过物种形成保护了结构创新,通过最小结构起步保证了搜索效率。这是一种强大且通用的神经进化方法。