Born to Learn: the Inspiration, Progress, and Future of Evolved Plastic Artificial Neural Networks
作者: Alessandro Soltoggio, Kevin O. Stanley, Sebastian Risi
发表: 2018-08
链接:https://arxiv.org/abs/1703.10371
1. Introduction
生物神经网络的非凡计算能力是由进化(Evolution)、发育(Development)和终身学习(Lifelong Learning)共同塑造的。受此启发,进化可塑性人工神经网络(Evolved Plastic Artificial Neural Networks, EPANNs) 利用计算机模拟的进化过程来培育具有可塑性的神经网络,旨在自主设计和创建学习系统。
EPANNs 结合了先天属性(由进化决定)和后天适应能力(通过可塑性响应环境经验)。其核心目标包括:
* 自主创建学习系统
* 从零开始引导学习(Bootstrap learning)
* 在未见过的环境中恢复性能
* 测试特定神经组件的计算优势
* 推导生物学习涌现的假设
2. Inspiration
EPANNs 的灵感主要来自以下四个方面:
- 自然与人工进化过程:模拟自然选择,通过进化计算(Evolutionary Computation)在计算机中涌现智能。
- 生物神经网络的可塑性:
- 赫布理论(Hebbian Theory):"Fire together, wire together"。
- 脉冲时序依赖可塑性(STDP)。
- 结构可塑性(Structural Plasticity):神经元之间新通路的建立。
- 神经调控(Neuromodulation):多巴胺等化学物质对神经功能的调节。
- 人工神经网络的可塑性:
- 监督学习(如反向传播)。
- 无监督学习(如 SOM, RBM, Hebbian规则)。
- 强化学习与奖励机制。
- 终身学习环境:从简单的输入输出映射到复杂的动态环境、具身智能(Embodied Intelligence)和开放式环境。
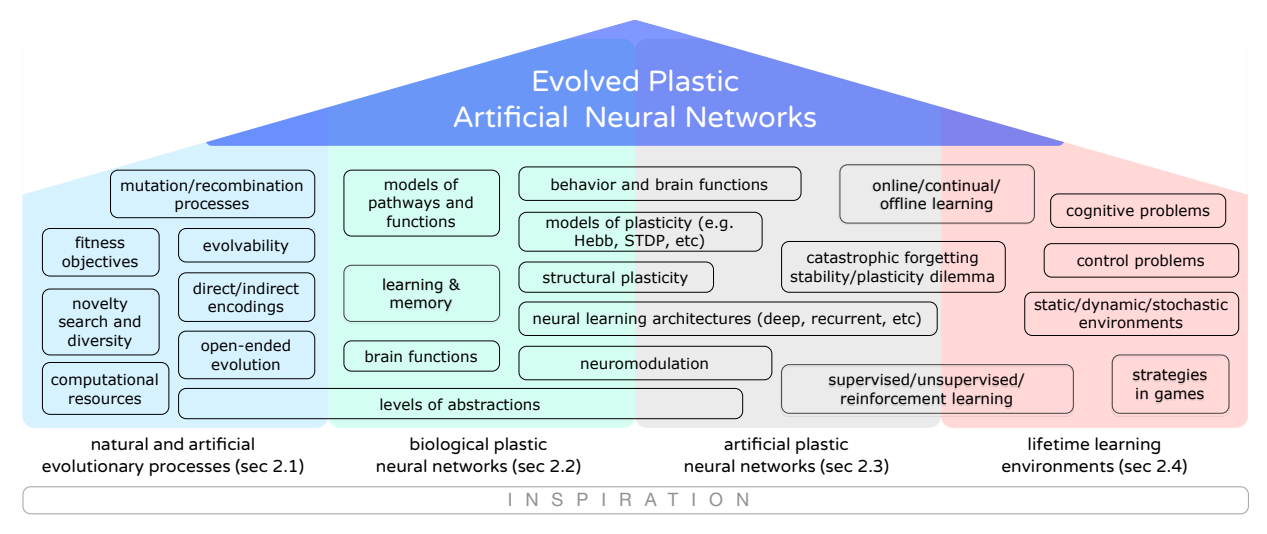
图 1: EPANNs 的灵感来源概览:进化过程、生物可塑性、人工可塑性和学习环境。
3. EPANNs Properties & Algorithms
3.1 Core Properties
EPANNs 被定义为具有以下属性的人工神经网络:
1. 进化 (Evolution):网络的某些部分由进化算法决定。
2. 可塑性 (Plasticity):处理信号的函数部分会随信号传播而改变(即权重或结构是动态的)。
3. 学习的发现 (Discovery of learning):利用进化和可塑性的协同作用,自主发现学习动态,而非仅仅优化预设的学习规则。
4. 通用性 (Generality):上述属性独立于特定的学习问题或机制,旨在解决广泛的问题。
3.2 Ideal Properties of Evolutionary Algorithms
为了有效进化 EPANNs,进化算法通常需要具备:
* 可变的基因型长度:适应日益增长的复杂性。
* 间接编码 (Indirect Encoding):从紧凑的基因型映射到复杂的表型(类似 DNA 到生物体),支持规律性、重复和模块化(如 HyperNEAT, CPPN)。
* 有效的探索:通过突变和重组。
* 可塑性规则的遗传编码:将学习规则本身纳入进化搜索空间。
* 多样性与低选择压力:如新颖性搜索(Novelty Search),避免陷入局部最优,特别是在欺骗性(Deceptive)环境中。
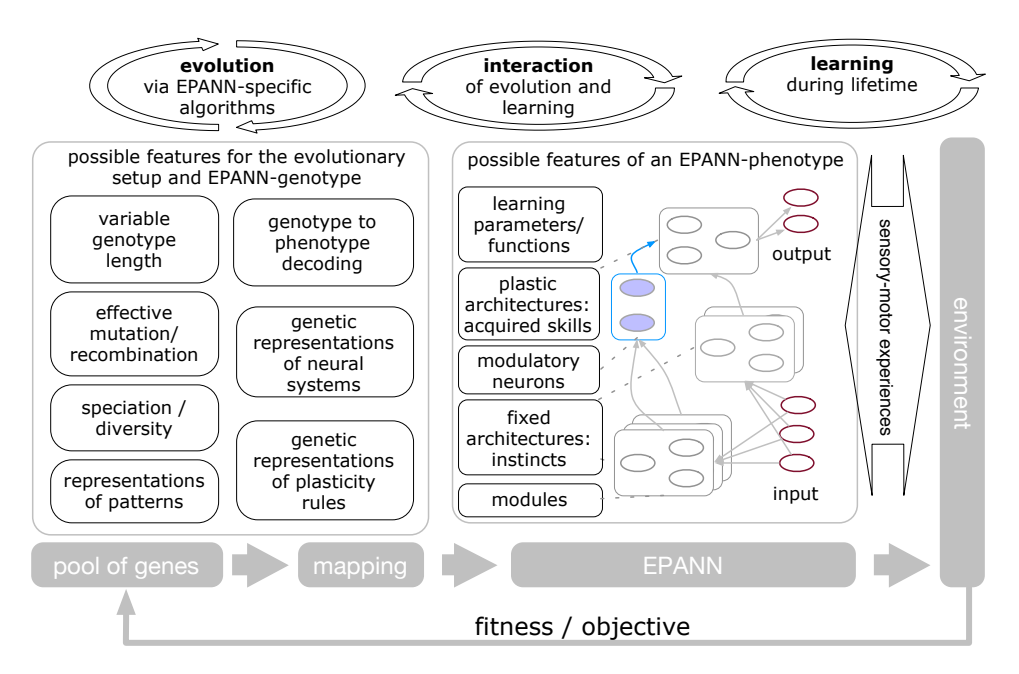
图 2: EPANN 实验设置的主要元素:模拟进化(左)与环境交互(右),中间是具有基因型和表型的 EPANN 个体。
4. Progress on Methodology
这是 EPANNs 研究的核心部分,涵盖了从简单的参数调整到复杂架构和元学习的进化。
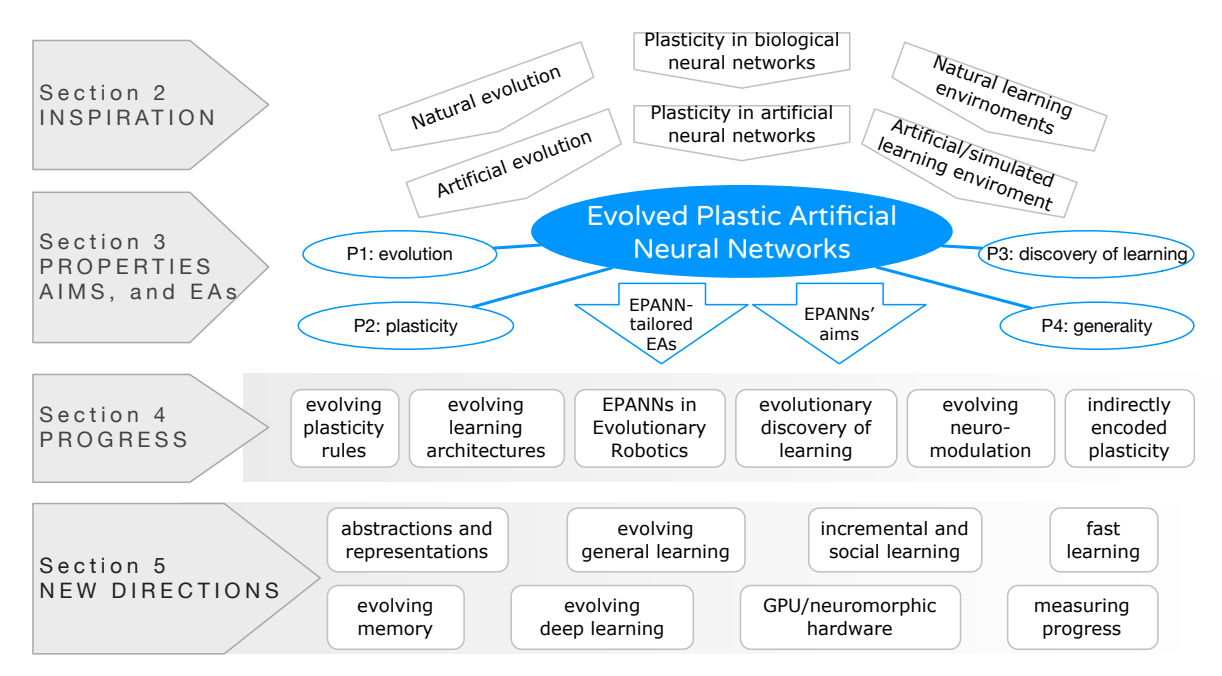
图 3: EPANNs 领域的组织结构与进展。
4.1 Evolving Plasticity Rules
早期的 EPANN 实验主要集中在为固定架构进化学习规则的参数。
学习规则通常表示为突触权重 $w$ 的变化量 $\Delta w$:
$$ \Delta w = f(\mathbf{x}, \theta) \tag{1} $$
其中:
* $\mathbf{x}$ 是神经信号向量(如突触前/后活动、当前权重、误差信号等)。
* $\theta$ 是由进化搜索确定的参数向量。
神经元的激活值 $x_i$ 通常由非线性函数 $\sigma$ 决定:
$$ x_i = \sigma\left(\sum_{j} (w_{ji} \cdot x_j)\right) \tag{2} $$
最简单的局部学习规则是 赫布规则 (Hebbian Plasticity):
$$ \Delta w = \eta \cdot x_j \cdot x_i \tag{3} $$
其中 $\eta$ 是学习率。
关键成果:
* 进化算法成功“重新发现”了著名的学习规则,如 Delta 规则(Chalmers, 1990)和 BCM 规则。
* 相比手工设计的规则,进化出的规则往往能更好地适应特定任务或展现出更强的通用性。
4.2 Evolving Neuromodulation
受生物学中多巴胺等神经调控机制的启发,EPANNs 引入了神经调控(Neuromodulation),即通过调节信号来控制可塑性的开启、关闭或强度。
引入调控信号 $m$ 后的学习规则变为:
$$ \Delta w = m \cdot f(\mathbf{x}, \boldsymbol{\theta}) \tag{4} $$
Soltoggio 等人 (2008) 提出了一种具体的进化规则形式,结合了赫布项及突触前/后项,并受调控信号 $m$ 的门控:
$$ \Delta w = m \cdot (A x_i x_j + B x_j + C x_i + D) \tag{5} $$
其中 $A, B, C, D$ 是进化参数。
机制与优势:
* 空间选择性:调控神经元可以针对性地调节网络中特定区域的可塑性。
* 时间选择性:仅在特定事件(如获得奖励或惩罚)发生时触发学习。
* 实验结果:在动态奖励环境(如 T-Maze 任务)中,带神经调控的网络比标准塑性网络进化得更快,表现更好,并能有效解决“灾难性遗忘”问题。
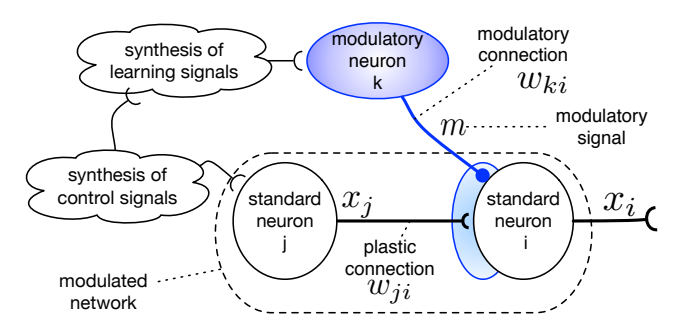
图 4: 神经调控示意图。调控神经元(Modulatory neuron)不直接传递信息,而是调节突触后神经元(Postsynaptic neuron)的突触可塑性。
4.3 Evolutionary Discovery of Learning
在非平稳环境(Non-stationary environments)中,个体必须在生命周期内学习才能适应。研究表明,进化过程呈现出明显的阶段性:
- 非学习阶段:种群尚未获得学习能力。
- 发现学习:通过突变,某个体偶然获得了某种利用奖励信号修改权重的机制。
- 优化阶段:学习机制被迅速传播并优化。
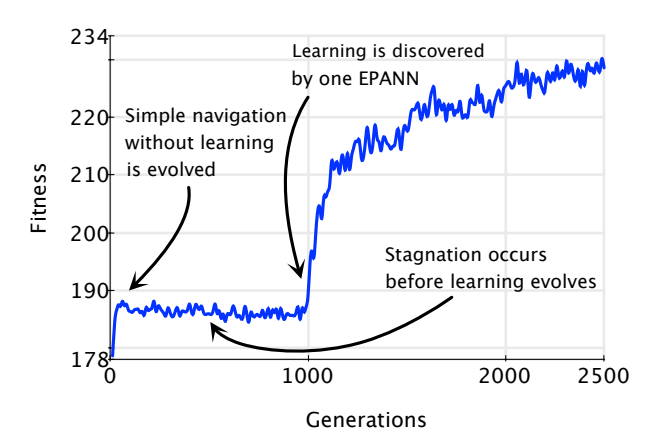
图 5: 进化过程中学习策略的发现。在非平稳环境中,进化在约 1000 代时突然发现了一种利用奖励信号的学习策略,导致适应度(Fitness)骤增。
新颖性搜索 (Novelty Search):
传统的适应度函数在某些任务(如迷宫导航)中具有欺骗性。Risi 等人 (2010) 表明,直接奖励行为的新颖性而非单纯的性能,反而能更有效地进化出具备学习能力的神经网络。
4.4 Indirectly Encoded Plasticity
为了扩展到大规模网络,EPANNs 采用间接编码(如 HyperNEAT)。
- CPPN (Compositional Pattern Producing Networks):作为基因型,CPPN 是一种函数 $f(x_1, y_1, x_2, y_2)$,输入神经元在空间中的坐标,输出它们之间的连接权重。
- Adaptive HyperNEAT:将此概念扩展到可塑性。CPPN 不仅决定初始权重,还决定该连接的学习规则(或学习参数)。这意味着网络的不同部分可以根据其几何结构演化出不同的局部学习规则模式。
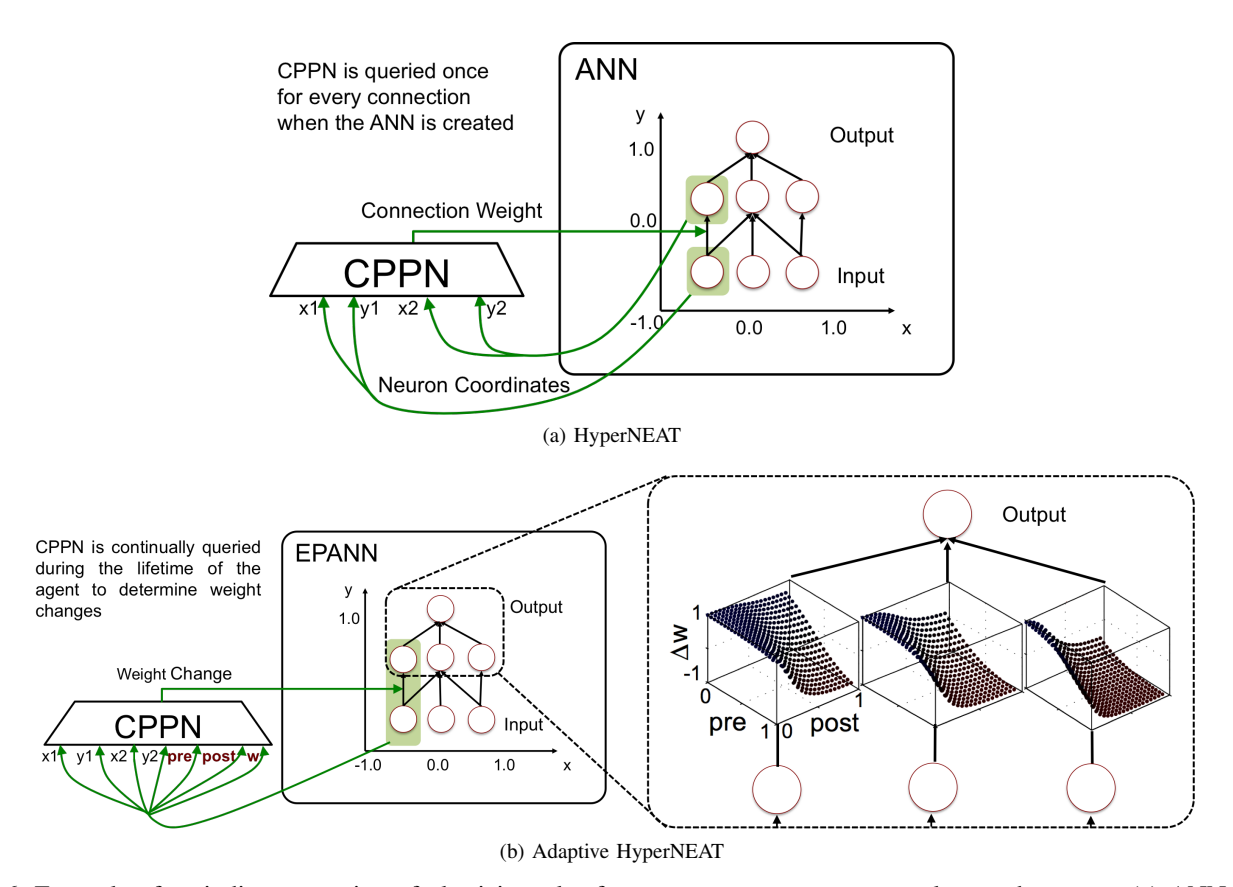
图 6: 间接编码可塑性示例 (Adaptive HyperNEAT)。CPPN (中) 接收神经元坐标作为输入,不仅输出初始权重,还输出该连接的学习规则参数。这使得由于几何规律,大规模网络 (右) 可以具有重复或对称的学习规则分布。
5. Future Directions
- 抽象层次与表示 (Levels of Abstraction):寻找合适的神经元和网络模型抽象级别,平衡计算成本与动力学丰富性。
- 通用学习 (General Learning):从进化“行为切换器”(Behavioral switches)迈向真正的通用突触学习能力,能够处理进化过程中未曾遇见的全新问题。
- 增量与社会学习 (Incremental & Social Learning):解决灾难性遗忘,利用模块化、记忆重放或社会交互(模仿、教学)来积累知识。
- 快速学习 (Fast Learning):模仿人类的单次学习(One-shot learning)和元认知能力,可能结合慢速和快速学习组件(互补学习系统)。
- 进化记忆 (Evolving Memory):结合外部记忆结构(如神经图灵机 NTM、LSTM),使进化网络具备长期显式记忆能力。
- 深度学习与 EPANNs:结合深度学习的强表征能力与进化的架构搜索/超参数优化能力(Neuroevolution of Deep Learning)。
- 硬件实现:利用 GPU 并行计算和神经形态硬件(Neuromorphic hardware,如忆阻器)加速 EPANNs 的进化与推理。
- 评估指标:建立超越单一任务性能的综合指标,包括恢复时间、任务多样性、样本效率、鲁棒性等。
6. Conclusion
EPANNs 代表了人工智能中一个极具野心的方向:让机器不只是学习特定的任务,而是通过进化“学会如何学习”(Learn to learn)。通过融合生物进化的智慧和现代计算能力,EPANNs 正在从简单的参数优化工具转变为能够自主设计复杂、通用、终身学习系统的强大方法。随着深度学习、硬件加速和新颖进化算法的结合,EPANNs 有望揭示生物智能涌现的原理,并创造出真正具有适应性的人工智能。