Brain-inspired replay for continual learning with artificial neural networks
来源: Nature Communications 2020
Abstract
ANN 面临一个叫做灾难性遗忘的问题(英文叫Catastrophic Forgetting),也就是一个网络在被训练学习新的东西的时候,会迅速遗忘之前学习过的东西。在人脑中,目前认为通过象征这些记忆的神经元重激活来保护记忆。在ANN中,这种机制可以通过生成式重放来实现(英文名叫Generative Replay, GR),即训练一个生成模型来生成旧数据进行重放。
虽然GR在简单任务上表现出色,但扩展到具有许多任务或复杂输入(如自然图像)的问题上极具挑战性。本文提出了一种受大脑启发的重放变体(Brain-inspired Replay, BI-R),其中重放的是由网络自身上下文调节的反馈连接所生成的内部/隐藏表示(Internal/Hidden Representations)。该方法在无需存储真实数据的情况下,在CIFAR-100等挑战性基准上取得了SOTA性能,并为大脑中的重放提供了一个新的计算模型。
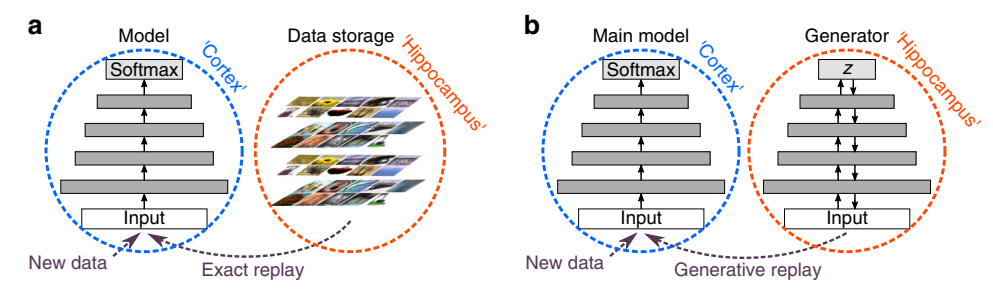
上图展示了现在模仿大脑进行replay的两种范式 (a) 精确重放(Experience Replay):将海马体视为存储缓冲器(类似于存储真实数据)。(b) 生成式重放(Generative Replay):将海马体视为生成网络,重放是一个生成过程。
结果 (Results)
1. 比较持续学习方法 (Comparing continual learning methods)
作者首先在 Split MNIST 任务上比较了GR与其他方法(如EWC, SI, LwF)。实验分为两种场景:
* 任务增量学习 (Task-IL):测试时知道任务ID(例如,只需区分当前任务内的数字)。
* 类增量学习 (Class-IL):测试时不知道任务ID(需要区分所有已学过的数字,例如10分类)。
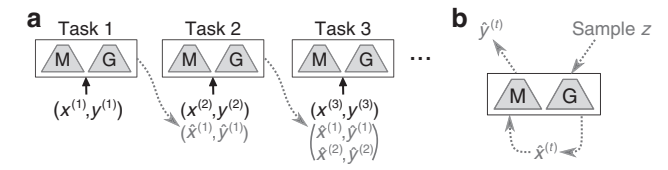
图2:生成式重放的训练协议。
(a) 学习新任务时,主模型[M]和生成器[G]首先生成重放样本,与当前任务数据混合训练。
(b) 重放样本通过从训练好的生成器采样,并由主模型打标签生成。
主要发现:
* 在 Task-IL 场景下,大多数方法(EWC, SI, LwF, GR)都能防止遗忘。
* 在更难的 Class-IL 场景下,只有 GR 能有效防止遗忘,基于正则化的方法(EWC, SI)完全失败。这表明Class-IL可能必须需要重放。
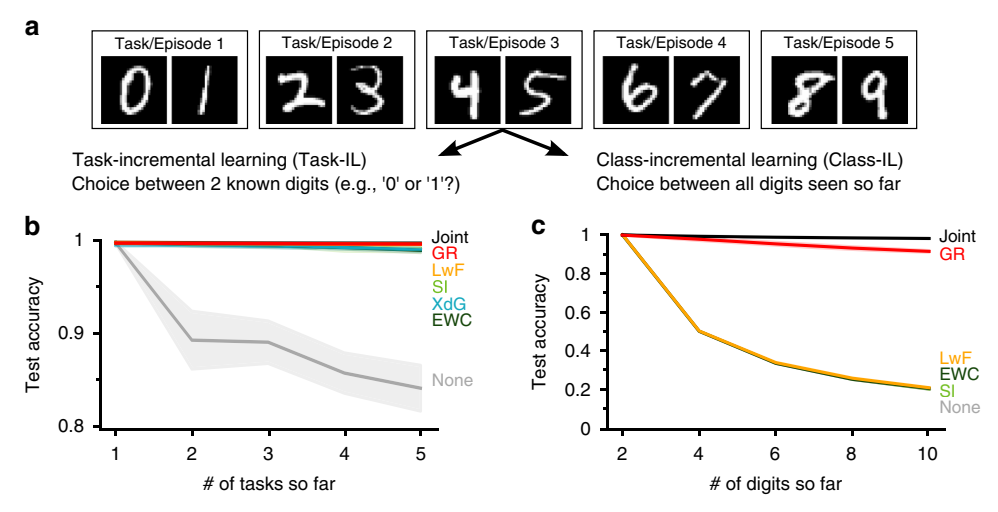
图3:Class-IL场景需要重放。
(b) Task-IL中各方法表现良好。(c) Class-IL中只有GR有效。
2. 生成式重放的效率和鲁棒性 (Efficiency and robustness of generative replay)
人们常担心GR效率低且需要高质量生成模型。作者通过实验挑战了这一观点:
* 数量:即使每个mini-batch只重放1个样本,GR在Class-IL中依然优于非重放方法。
* 质量:即使使用极低容量的VAE(10个隐藏单元)生成模糊图像,GR的性能也仅受到轻微影响。
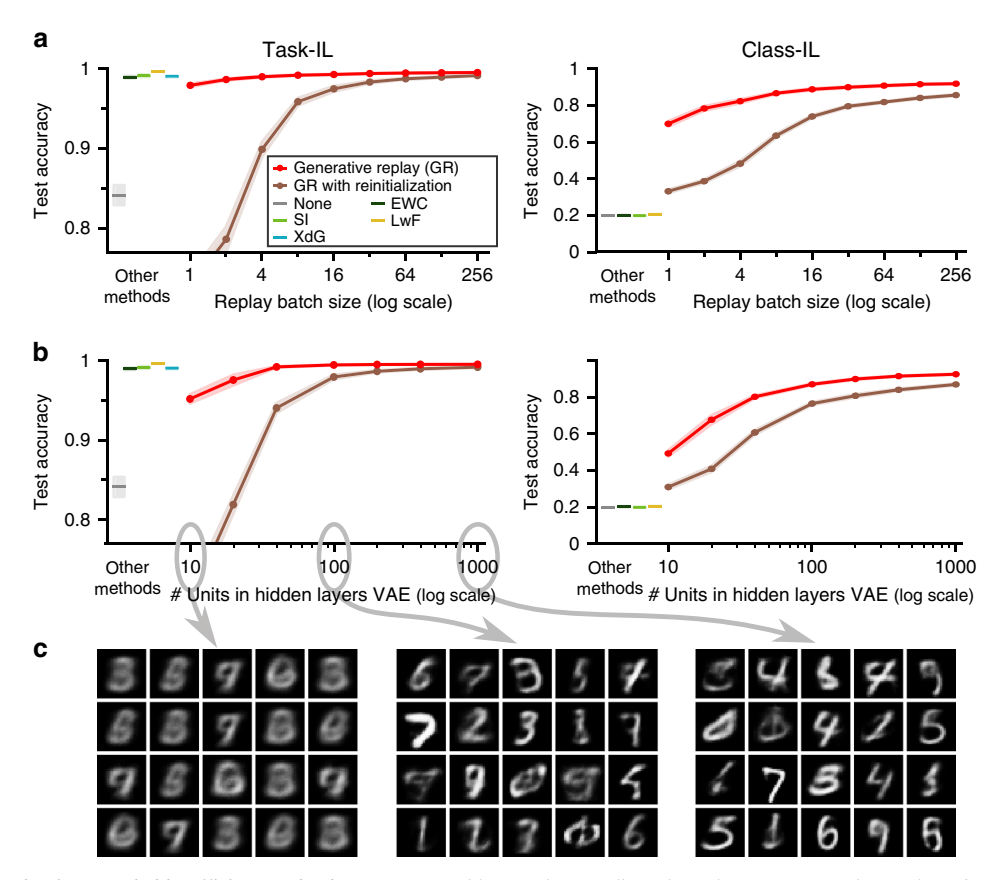
图4:GR的高效与鲁棒。
(a) 重放样本数量的影响。(b) VAE隐藏层单元数(质量)的影响。(c) 低质量重放样本示例。
这表明重放不必完美,只要"足够好"即可。
3. 扩展到更具挑战性的问题 (Scaling up to more challenging problems)
虽然GR在MNIST上表现良好,但在更复杂的问题上,标准GR也会失败:
1. Permuted MNIST (100个任务):标准GR在约15个任务后性能迅速下降。
2. Split CIFAR-100 (自然图像):标准GR在Task-IL和Class-IL场景下都表现很差,生成的图像质量太低。
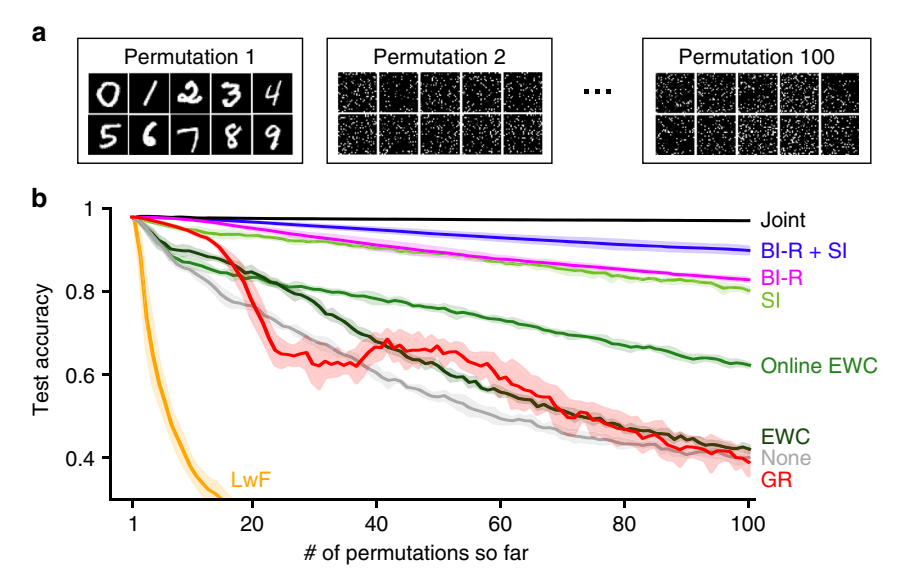
图5:Permuted MNIST (100个任务)。
标准GR(红线)无法扩展到大量任务。作者提出的脑启发重放(BI-R,蓝线)及其与SI的结合(紫线)表现优异。
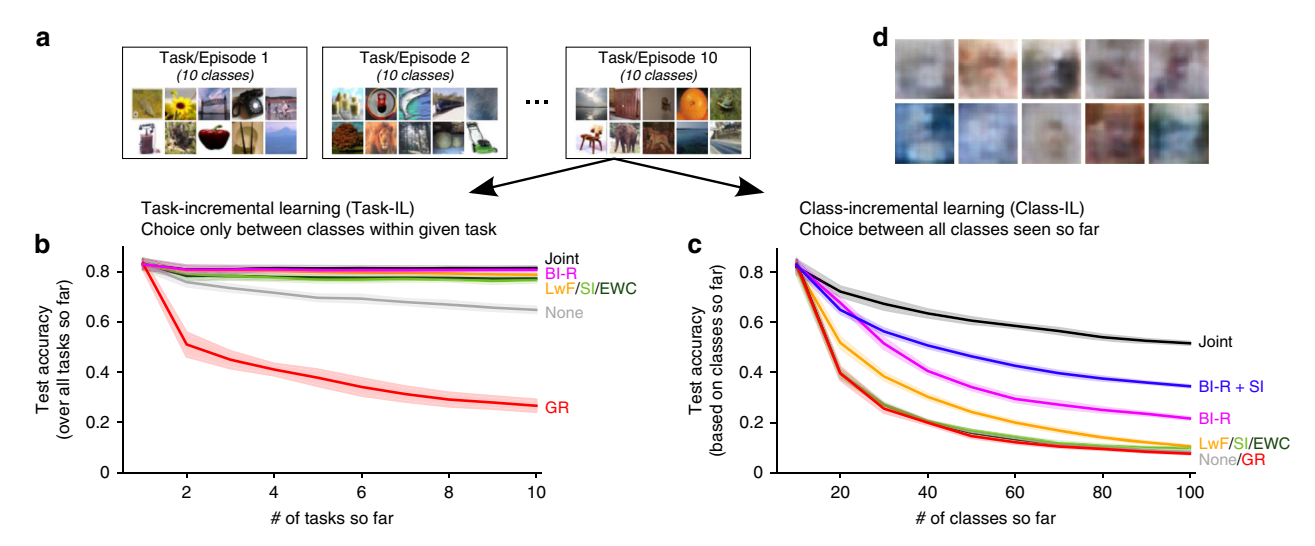
图6:Split CIFAR-100。
(b) Task-IL场景。(c) Class-IL场景。只有BI-R能在此场景下防止灾难性遗忘。
(d) 标准GR生成的CIFAR图像质量极差。
脑启发的重放改进 (Brain-inspired modifications to GR)
为了解决扩展性问题,作者受大脑启发,对GR进行了五项关键改进:
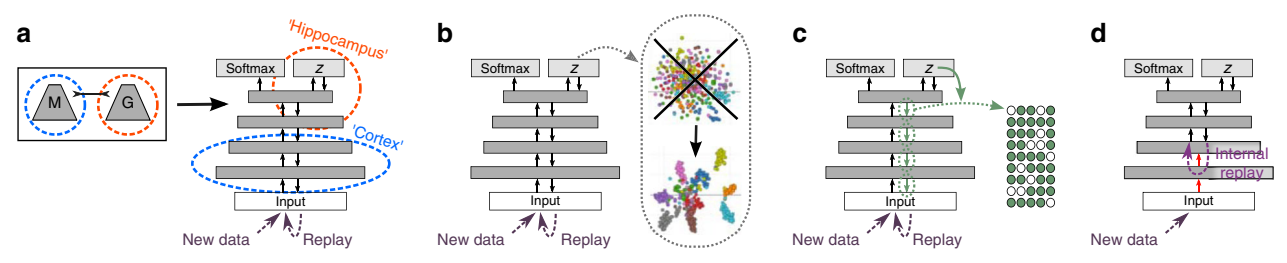
图7:脑启发的五项改进。
-
通过反馈重放 (Replay-through-feedback, RtF):
- 灵感: 大脑皮层与海马体之间存在反馈连接。
- 方法: 不使用单独的生成模型,而是将生成器通过反馈连接合并到主模型中(类似于VAE结构,共享编码器/主模型前几层)。
-
条件重放 (Conditional Replay):
- 灵感: 人类可以控制回忆特定的记忆。
- 方法: 使用高斯混合模型 (GMM) 替代标准正态分布作为隐变量的先验,每个类对应一个模态,从而允许按类生成样本。
-
基于内部上下文的门控 (Gating based on internal context):
- 灵感: 大脑根据上下文处理刺激。
- 方法: 在解码器(生成路径)中使用上下文相关的门控 (Gating),根据要生成的类抑制部分神经元。
-
内部重放 (Internal Replay):
- 灵感: 心理意象通常不会重放到视网膜(像素)级别,而是在高级皮层。
- 方法: 不重放原始像素,而是重放隐藏层(抽象)表示。例如,固定预训练的卷积层,只重放全连接层的特征。
-
蒸馏 (Distillation):
- 灵感: 知识蒸馏。
- 方法: 对重放样本使用软标签 (Soft targets)(预测概率向量)而非硬标签,保留类间关系的不确定性。
评估与分析 (Evaluation & Analysis)
性能评估
- 在 Permuted MNIST (100任务) 上,BI-R 达到了 SOTA,结合 SI 后效果更好(图5)。
- 在 CIFAR-100 (Class-IL) 上,BI-R 是唯一在不存储数据情况下取得合理性能的方法(图6)。
消融实验 (Lesion experiments)
作者通过逐一移除组件来分析其贡献:
* Internal Replay (int) 对性能贡献最大。
* 所有组件在不同程度上都是必要的,且相互补充。
* RtF 主要提高了参数效率(无需独立生成器)。
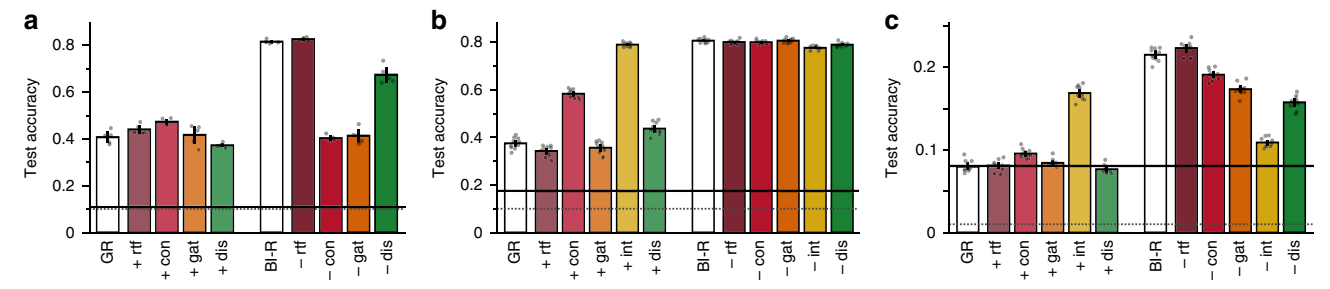
图8:消融实验。
展示了各组件对Permuted MNIST和CIFAR-100性能的贡献。
生成样本质量 (Quality of generated replay)
使用改进的 Inception Score (IS) 和 Fréchet Inception Distance (FID) 以及 Precision & Recall 曲线评估:
* BI-R 生成的样本(内部表示)在质量 (Precision) 和 多样性 (Recall) 上均显著优于标准 GR。
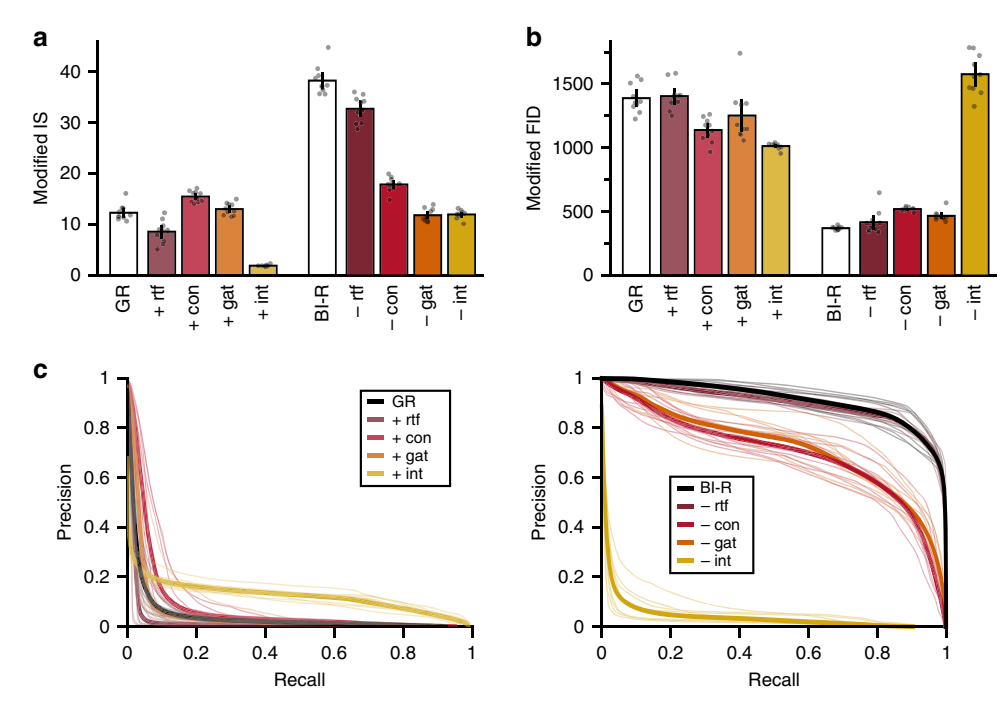
图9:生成样本的质量与多样性。
BI-R(蓝色)在各项指标上均优于标准GR(红色)。
讨论 (Discussion)
- 重放的必要性:Class-IL 场景下,重放似乎是不可避免的。
- 效率:重放不需要大量或完美的样本。
- 互补性:基于参数空间的正则化(如SI)和基于函数空间的重放(GR)是互补的策略,类似于大脑中的突触巩固和系统巩固。
- 生物学意义:该模型支持“大脑中的重放是一个生成过程”的假说,而非简单的回放存储的记忆。
方法细节 (Detailed Methods)
任务协议 (Task Protocols)
- Split MNIST: 将MNIST数据集分为5个任务,每个任务包含2个数字。使用原始28x28灰度图像。
- Permuted MNIST: 使用零填充将MNIST图像变为32x32,对每个任务的1024个像素应用不同的随机排列。共100个任务,每个任务都是10分类。
- Split CIFAR-100: 将CIFAR-100分为10个任务,每个任务10个类。使用32x32 RGB图像,进行了标准化处理。
网络架构 (Network Architecture)
为了公平比较,所有方法使用相同的基础网络架构:
* Split MNIST: 全连接网络,2个隐藏层,每层400个节点,ReLU激活。
* Permuted MNIST: 全连接网络,2个隐藏层,每层2000个节点。
* Split CIFAR-100: 5个预训练的卷积层(在CIFAR-10上预训练),后接2个全连接层(每层2000节点)。
Softmax输出层的处理取决于场景:
* Task-IL: 多头输出(Multi-headed),仅当前任务或重放任务对应的输出单元激活。
* Class-IL: 单头输出(Single-headed),所有已遇类别的输出单元都激活。
* Domain-IL: 单头输出,所有输出单元始终激活。
训练 (Training)
- 优化器: ADAM (beta1=0.9, beta2=0.999)。
- 损失函数: 任务特定的损失函数 $\mathcal{L}_{total}$,通常包含当前任务数据的分类损失 $\mathcal{L}_{current}$。如果使用重放,还包含重放数据的损失 $\mathcal{L}_{replay}$。
- Mini-batch: Split MNIST为128,其他为256。
生成式重放 (Generative Replay, GR) 实现
- 主模型 (Main Model): 用于解决任务的分类器。
- 生成模型 (Generative Model): 标准GR使用一个独立的对称变分自编码器 (VAE)。
- 架构: 编码器和解码器通常与主模型架构相似。
- 训练: 最大化变分下界 (ELBO)。
- 重放: 从生成模型采样,由主模型打标签(硬标签)。
脑启发的重放改进 (Brain-inspired Modifications)
1. 通过反馈重放 (Replay-through-feedback, RtF)
- 模型: 将生成器合并到主模型中,实现为一个VAE + 分类层(位于编码器末端)。
- 优点: 只需训练一个模型,参数效率更高。
- 损失函数: $\mathcal{L}_{current}^{RtF} = \mathcal{L}^C \text{(分类)} + \mathcal{L}^G \text{(生成)}$。
2. 条件重放 (Conditional Replay)
- 目的: 生成特定类别的样本。
- 方法: 将隐变量 $\mathbf{z}$ 的先验分布从标准正态分布改为高斯混合模型 (GMM): $p(\mathbf{z}) = \sum p(Y=c) \mathcal{N}(\mu^c, \sigma^c \mathbf{I})$。每个类 $c$ 都有独立的可训练均值 $\mu^c$ 和方差 $\sigma^c$。
- 生成: 随机选择一个类 $y$,从对应的模态 $\mathcal{N}(\mu^y, \sigma^{y^2}\mathbf{I})$ 中采样 $\mathbf{z}$。
3. 基于内部上下文的门控 (Gating based on internal context)
- 方法: 对每个任务(Permuted MNIST)或每个类(CIFAR-100),随机选择解码器隐藏层中 X% 的神经元进行抑制(置零)。
- 条件: 只有在解码器部分使用门控,根据要生成的特定类或任务上下文应用对应的Mask。
4. 内部重放 (Internal Replay)
- 方法: 移除VAE解码器中的反卷积层,直接在全连接层输出的隐藏层表示 (Hidden Representations) 上计算重建误差。
- 预训练: 对于CIFAR-100,卷积层在CIFAR-10上预训练并冻结,只重放全连接层的特征。这模拟了成人视觉皮层早期的稳定性。
- 损失: 重建损失变为隐藏层激活值的均方误差 (MSE)。
5. 蒸馏 (Distillation)
- 方法: 使用软标签 (Soft Targets) 代替硬标签。
- 温度 (Temperature): 在生成标签和计算蒸馏损失时,将Softmax的温度参数设为 T=2,以使概率分布更平滑,保留更多类间信息。
- 损失: $\mathcal{L}^D(\mathbf{x}, \tilde{\mathbf{y}}) = -T^2 \sum \tilde{\mathbf{y}}_c \log p_\theta^T(Y=c|\mathbf{x})$。
正则化基线方法 (Regularization-based Baselines)
- SI (Synaptic Intelligence): 维护每个参数的重要性权重 $\Omega$,在损失函数中加入正则项 $\sum \Omega_i (\theta_i - \theta_{old})^2$。
- EWC (Elastic Weight Consolidation): 使用Fisher信息矩阵对角线元素作为重要性权重。
- LwF (Learning without Forgetting): 重放当前任务的输入,使用旧模型的预测作为软标签。
生成器性能评估指标 (Evaluation Measures)
为了评估内部重放生成的样本质量,作者修改了标准指标:
* Modified IS (Inception Score): 使用与主模型架构相同的独立分类器作为Embedding网络。
* Modified FID (Fréchet Inception Distance): 计算真实数据和生成数据在Embedding空间中的特征分布距离。
* Precision & Recall: 分别评估生成样本的质量(Precision)和多样性(Recall)。