title: 1808.04873v1
source_pdf: /home/lzr/code/thesis-reading/1808.04873v1.pdf
Generalization of Equilibrium Propagation to Vector Field Dynamics
Benjamin Scellier^{1} , Anirudh Goyal^{1} , Jonathan Binas^{1} , Thomas Mesnard^{2} , Yoshua Bengio^{1}† 1 Mila, Université de Montréal 2 École Normale Supérieure de Paris †CIFAR Senior Fellow
August 16, 2018
Abstract
The biological plausibility of the backpropagation algorithm has long been doubted by neuroscientists. Two major reasons are that neurons would need to send two different types of signal in the forward and backward phases, and that pairs of neurons would need to communicate through symmetric bidirectional connections. We present a simple two-phase learning procedure for fixed point recurrent networks that addresses both these issues. In our model, neurons perform leaky integration and synaptic weights are updated through a local mechanism. Our learning method generalizes Equilibrium Propagation to vector field dynamics, relaxing the requirement of an energy function. As a consequence of this generalization, the algorithm does not compute the true gradient of the objective function, but rather approximates it at a precision which is proven to be directly related to the degree of symmetry of the feedforward and feedback weights. We show experimentally that our algorithm optimizes the objective function.
1 Introduction
Deep learning [LeCun et al., 2015] is the de-facto standard in areas such as computer vision [Krizhevsky et al., 2012], speech recognition [Hinton et al., 2012] and machine translation [Bahdanau et al., 2014]. These applications deal with different types of data and have little in common at first glance. Remarkably, all these models typically rely on the same basic principle: optimization of objective functions using the backpropagation algorithm. Hence the question: does the cortex in the brain implement a mechanism similar to backpropagation, which optimizes objective functions?
The backpropagation algorithm used to train neural networks requires a side network for the propagation of error derivatives, which is vastly seen as biologically implausible [Crick, 1989]. One hypothesis, first formulated by Hinton and McClelland [1988], is that error signals in biological networks could be encoded in the temporal derivatives of the neural activity and propagated through the network via the neuronal dynamics itself, without the need for a side network. Neural computation would correspond to both inference and error back-propagation. The present work also explores this idea.
Equilibrium Propagation [Scellier and Bengio, 2017a] requires the network dynamics to be derived from an energy function, enabling computation of an exact gradient of an objective function. However, in terms of biological realism, the requirement of symmetric weights between neurons arising from the energy function (the Hopfield energy) is not desirable. The work presented here is a generalization of Equilibrium Propagation to vector field dynamics, without the need for energy functions, gradient dynamics, or symmetric connections.
Our approach is the following.
-
- We start from standard models in neuroscience for the dynamics of the neuron's membrane voltage and for the synaptic plasticity (section 2). In particular, unlike in the Hopfield model [Hopfield, 1984], we do not assume pairs of neurons to have symmetric connections.
-
- We then describe a supervised learning algorithm for fixed point recurrent neural networks, based on these models (sections 3-4) and with few extra assumptions. Our model assumes two phases: at prediction time (first phase), no synaptic changes occur, whereas a local update rule becomes effective when the targets are observed (second phase).
-
- Finally, we attempt to show that the proposed algorithm optimizes an objective function (section 5) – a highly desirable property from the point of view of machine learning. We show this experimentally and we attempt to understand this theoretically, too.
2 Neuronal Dynamics
We denote by s^{i} the membrane voltage of neuron i, which is continuous-valued and plays the role of a state variable for neuron i. We suppose that ρ is a deterministic function
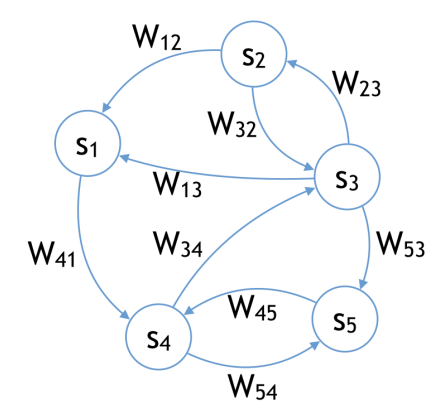
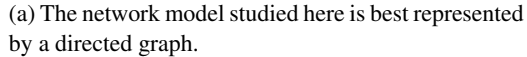
(b) The Hopfield model is best represented by an undirected graph.
Figure 1: From the point of view of biological plausibility, the symmetry of connections in the Hopfield model is a major drawback (1b). The model that we study here is, like a biological neural network, a directed graph (1a).
(nonlinear activation) that takes a scalar s^{i} as input and outputs a scalar ρ(si). The scalar ρ(si) represents the firing rate of neuron i. The synaptic strength from neuron j to neuron i is denoted by Wij .
2.1 Neuron Model
We consider the following time evolution for the membrane voltage s^{i} :
$$\frac{ds_i}{dt} = \sum_j W_{ij} \rho(s_j) - s_i. \tag{1}$$
Eq. 1 is a standard point neuron model (see e.g. Dayan and Abbott [2001]) in which neurons are seen as performing leaky temporal integration of their inputs. We will refer to Eq. 1 as the rate-based leaky integrator neuron model.
Unlike energy-based models such as the Hopfield model [Hopfield, 1984] that assume symmetric connections between neurons, in the model studied here the connections between neurons are not tied. Our model is represented by a directed graph, whereas the Hopfield model is best regarded as an undirected graph (Figure 1).
2.2 Plasticity Model
We consider a simplified Hebbian update rule based on preand post-synaptic activity, in which a change ds^{i} in the post-synaptic activity causes a change dWij in the synaptic strength given by
$$dW_{ij} \propto \rho(s_j)ds_i. \tag{2}$$
Bengio et al. [2017] have shown in simulations that this update rule can functionally reproduce Spike-Timing Dependent Plasticity (STDP). STDP is considered a key mechanism of synaptic change in biological neurons [Markram and Sakmann, 1995, Gerstner et al., 1996, Markram et al., 2012]. STDP is often conceived of as a spike-based process which relates the change in the synaptic weight Wij to the timing difference between postsynaptic spikes (in neuron i) and presynaptic spikes (in neuron j) [Bi and Poo, 2001]. In fact, both experimental and computational work suggest that postsynaptic voltage, not postsynaptic spiking, is more important for driving LTP (Long Term Potentiation) and LTD (Long Term Depression) [Clopath and Gerstner, 2010, Lisman and Spruston, 2010].
Throughout this paper we will refer to Eq. 2 as STDPcompatible weight change and propose a machine learning justification for such an update rule.
2.3 Vector Field µ in the State Space
In this subsection we rewrite Eq. 1 and Eq. 2 at a higher level of abstraction. Let s = (s1, s2, . . .) be the global state variable and let θ = (Wij ) i,j be the parameter variable consisting of the set of synaptic weights. We write µθ(s) the vector whose components µθ,i(s) are defined as
$$\mu_{\theta,i}(s) := \sum_{j} W_{ij} \rho(s_j) - s_i. \tag{3}$$
The vector µθ(s) has the same dimension as the state variable s. For fixed θ, the mapping s 7→ µθ(s) is a vector field in the state space, which indicates in which direction each neuron's activity changes. Eq. 1 rewrites
$$\frac{ds}{dt} = \mu_{\theta}(s). \tag{4}$$
Let us move on to the weight change of Eq. 2. Since $\rho(s_j) = \frac{\partial \mu_{\theta,i}}{\partial W_{ij}}(s)$ , the weight change can be expressed as $dW_{ij} \propto \frac{\partial \mu_{\theta,i}}{\partial W_{ij}}(s)ds_i$ . Note that for all $i' \neq i$ we have $\frac{\partial \mu_{i'}}{\partial W_{ij}} = 0$ since to each synapse $W_{ij}$ corresponds a unique post-synaptic neuron $s_i$ . Hence $dW_{ij} \propto \frac{\partial \mu_{\theta}}{\partial W_{ij}}(s) \cdot ds$ . We rewrite the STDP-compatible weight change (Eq. 2) in the concise form
$$d\theta \propto \frac{\partial \mu_{\theta}}{\partial \theta} (s)^T \cdot ds. \tag{5}$$
3 Fixed Point Recurrent Neural Networks for Supervised Learning
We consider the supervised setting in which we want to predict a target y given an input x. The units of the network are split in two sets: the 'input' units x whose values are always clamped, and the dynamically evolving units s (the neurons activity, indicating the state of the network), which themselves include the hidden layers ( $s_1$ and $s_2$ here) and an output layer ( $s_0$ here), as in Figure 3. In this context the vector field $\mu_{\theta}$ is defined by its components $\mu_{\theta,0}$ , $\mu_{\theta,1}$ and $\mu_{\theta,2}$ on $s_0$ , $s_1$ and $s_2$ respectively, as follows:
$$\mu_{\theta,0}(\mathbf{x},s) = W_{01} \cdot \rho(s_1) - s_0, \tag{6}$$
$$\mu_{\theta,1}(\mathbf{x},s) = W_{12} \cdot \rho(s_2) + W_{10} \cdot \rho(s_0) - s_1, \quad (7)$$
$$\mu_{\theta,2}(\mathbf{x},s) = W_{23} \cdot \rho(\mathbf{x}) + W_{21} \cdot \rho(s_1) - s_2. \tag{8}$$
In its original definition, $\rho$ takes a scalar as input and outputs a scalar, but here we generalize the definition of $\rho$ to act on a vector (i.e. a layer of neurons), in which case it returns a vector of the same dimension, operating element-wise on the coordinates of the input vector.
The neurons s follow the dynamics
$$\frac{ds}{dt} = \mu_{\theta}(\mathbf{x}, s). \tag{9}$$
Unlike in the continuous Hopfield model, here the feedforward and feedback weights are not tied, and in general the dynamics of Eq. 9 is not guaranteed to converge to a fixed point. However, for simplicity of presentation we assume here that the dynamics of the neurons converge to a fixed point which we denote by $s_{\theta}^{\mathbf{x}}$ . The fixed point $s_{\theta}^{\mathbf{x}}$ implicitly depends on $\theta$ and $\mathbf{x}$ through the relationship
$$\mu_{\theta}\left(\mathbf{x}, s_{\theta}^{\mathbf{x}}\right) = 0. \tag{10}$$
In addition to the vector field $\mu_{\theta}(\mathbf{x},s)$ , a cost function C(y,s) measures how good or bad a state s is with respect to the target y. In our model, the layer $s_0$ has the same dimension as the target y and plays the role of the 'output' layer where the prediction is read. The discrepancy between the output layer $s_0$ and the target y is measured by
the quadratic cost function
$$C(y,s) = \frac{1}{2} \|y - s_0\|^2$$
. (11)
The prediction is then read out on the output layer at the fixed point and compared to the target y. The objective function that we aim to minimize (with respect to $\theta$ ) is the cost at the fixed point $s_A^x$ , which we write 1
$$J(\mathbf{x}, \mathbf{y}, \theta) := C(\mathbf{y}, s_{\theta}^{\mathbf{x}}). \tag{12}$$
Almeida [1987] and Pineda [1987] proposed an algorithm known as Recurrent Backpropagation $^2$ to optimize J by computing the gradient $\frac{\partial J}{\partial \theta}(x,y,\theta)$ . This algorithm, presented in Appendix B, is based on extra assumptions on the neuronal dynamics which make it biologically implausible.
In this paper, our approach to optimize J is to give up on computing the true gradient of J and, instead, we propose a simple algorithm based on the leaky integrator dynamics (Eq. 4) and the STDP-compatible weight change (Eq. 5). We will show in section 5 that our algorithm computes a proxy to the gradient of J.
Also, note that in its general formulation, our algorithm applies to any vector field $\mu_{\theta}(\mathbf{x}, s)$ and cost function $C_{\theta}(\mathbf{y}, s)$ , even when C depends on $\theta$ (Appendix A).
4 Equilibrium Propagation in the Vector Field Setting
We describe a simple two-phase learning procedure based on the state dynamics (Eq. 4) and the parameter change (Eq. 5). This algorithm generalizes the one proposed in Scellier and Bengio [2017a].
4.1 Augmented Vector Field
In its original (energy-based) version, the central idea of Equilibrium Propagation [Scellier and Bengio, 2017a] is to see the cost function C (Eq. 11) as an 'external potential energy' for the output layer $s_0$ , which can drive it towards the target y. Following the same idea we define the augmented vector field
$$\mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s) := \mu_{\theta}(\mathbf{x}, s) - \beta \frac{\partial C}{\partial s}(\mathbf{y}, s), \tag{13}$$
where $\beta \geq 0$ is a real-valued scalar which we call the influence parameter (or clamping factor). Rather than Eq. 9, the
<sup>1More generally, in order to take into account cases when the dynamics of Eq. 9 does not converge to a fixed point, we can define the objective function as the average cost of the state along the trajectory (over infinite duration).
<sup>2'Recurrent backprop' is a special case of 'backprop through time', specialized to a fixed point recurrent network (i.e. an RNN whose dynamics converges to a fixed point, like those studied here).
dynamics of s is more generally
$$\frac{ds}{dt} = \mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s) \tag{14}$$
for some value of $\beta$ . The parameter $\beta$ controls whether the output layer $s_0$ is pushed towards the target y or not, and by how much. In particular, the dynamics of Eq. 9 corresponds to the case $\beta=0$ .
The augmented vector field can be seen as a sum of two 'forces' that act on the temporal derivative of the state variable s. Apart from the vector field $\mu_{\theta}$ that models the interactions between neurons within the network, an 'external force' $-\beta \frac{\partial C}{\partial s}$ is induced by the 'external potential' $\beta C$ and acts on the output layer:
$$-\beta \frac{\partial C}{\partial s_0}(\mathbf{y}, s) = \beta(\mathbf{y} - s_0), \tag{15}$$
$$-\beta \frac{\partial C}{\partial s_i}(\mathbf{y}, s) = 0, \qquad \forall i \ge 1. \tag{16} $$
The form of Eq. 15 suggests that when $\beta=0$ , the output layer $s_0$ is not sensitive to the target y. When $\beta>0$ , the 'external force' drives the output layer $s_0$ towards the target y. The case $\beta\to\infty$ (not studied in this paper) would correspond to fully clamped output units.
Following the dynamics of Eq. 14, the state variable s eventually settles to a fixed point $s^{\beta}_{\theta}$ characterized by
$$\mu_{\theta}^{\beta}\left(\mathbf{x}, \mathbf{y}, s_{\theta}^{\beta}\right) = 0. \tag{17}$$
Note that the fixed point $s_{\theta}^{\beta}$ also depends on x and y but we omit to write the dependence to keep readable notations. In particular for $\beta=0$ we have $s_{\theta}^{0}=s_{\theta}^{x}$ .
4.2 Algorithm
We propose the following two-phase learning procedure. At prediction time (the first phase), the input units are set (clamped) to the input values x, and the influence parameter $\beta$ is set to 0. The state variable s (all the other neurons) follows the dynamics of Eq. 14 and settles to the first fixed point $s_{\theta}^{0}$ . During this phase, we assume that the synaptic weights are unchanged.
At training time (the second phase), the input units are still clamped and the influence parameter $\beta$ takes on a small positive value $\beta\gtrsim 0$ . The state variable follows the dynamics of Eq. 14 for that new value of $\beta$ , and the synaptic weights are assumed to follow the STDP-compatible weight change of Eq. 5. The network eventually settles to a new nearby fixed point, denoted $s_{\theta}^{\beta}$ , corresponding to the new value $\beta\gtrsim 0$ .
4.3 Backpropagation of Error Signals
In the first phase, the influence parameter $\beta$ is equal to 0. The output units are 'free', in the sense that they are not
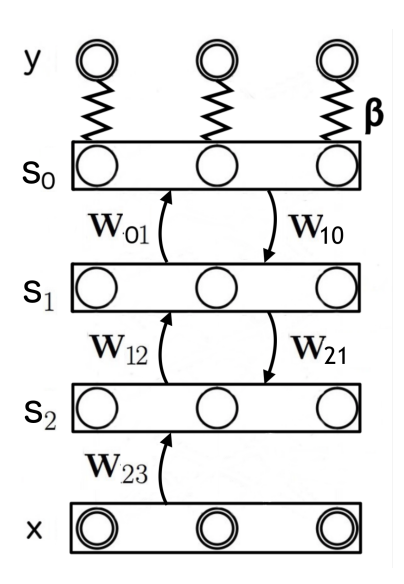
Figure 2: Graph of the network. Input x is clamped. Neurons s include hidden layers $s_2$ and $s_1$ , and output layer $s_0$ that corresponds to the layer where the prediction is read. Target y has the same dimension as $s_0$ . The clamping factor $\beta$ scales the 'external force' $-\beta \frac{\partial C}{\partial s}$ that attracts the output layer's state $s_0$ towards the target y.
influenced by the target y.
In the second phase, the influence parameter takes on a positive value $\beta \gtrsim 0$ . The novel 'external force' $-\beta \frac{\partial C}{\partial s}(y,s)$ in the dynamics of Eq. 14 acts on the output units and drives them towards their targets (Eq. 15). This force models the observation of the target y: it nudges the output units $s_0$ from their value at the first fixed point in the direction of their targets. Since this force only acts on the output layer $s_0$ , the other hidden layers ( $s_i$ with i>0) are initially at equilibrium at the beginning of the second phase. The perturbation caused at the output layer ( $s_0$ ) will then propagate backwards along the layers of the network ( $s_1$ and $s_2$ ), giving rise to 'back-propagating' error signals.
A more detailed analysis of the second phase is carried out in Appendix B and a connection to the recurrent backpropagation algorithm [Almeida, 1987, Pineda, 1987] is established, following the ideas of Scellier and Bengio [2017b].
5 Optimization of the Objective Function
The proposed algorithm (section 4.2) is experimentally found to optimize the objective function $J(\theta)$ (see Appendix C). In this section, we attempt to understand why.
5.1 Vector Field $\nu$ in the Parameter Space
Our model assumes that the STDP-compatible weight change occurs during the second phase of training, when the network's state moves from the first fixed point $s_{\theta}^{0}$ to the second fixed point $s^{\beta}_{\theta}$ . Integrating Eq. 5 from $s^{0}_{\theta}$ to $s^{\beta}_{\theta}$ , normalizing it by a factor $\beta$ and letting $\beta \to 0$ , we get the update rule
$$\Delta\theta \propto \nu(x, y, \theta), \tag{18} $$
where $\nu(x, y, \theta)$ is the vector defined as 3
$$\nu(\mathbf{x}, \mathbf{y}, \theta) := \frac{\partial \mu_{\theta}}{\partial \theta} \left( \mathbf{x}, s_{\theta}^{0} \right)^{T} \cdot \left. \frac{\partial s_{\theta}^{\beta}}{\partial \beta} \right|_{\beta = 0}. \tag{19}$$
The vector $\nu(x, y, \theta)$ has the same dimension as $\theta$ . Thus, for fixed x and y, the mapping $\theta \mapsto \nu(x, y, \theta)$ defines a vector field in the parameter space. We show next that $\nu(x, y, \theta)$ is a proxy to the gradient $-\frac{\partial J}{\partial \theta}(x, y, \theta)$ .
The Vector Field $\nu$ As A Proxy For The Gradient
Theorem 1. The gradient $\frac{\partial J}{\partial \theta}(x, y, \theta)$ and the vector field $\nu(x, y, \theta)$ can be expressed explicitly in terms of $\mu_{\theta}$ and C:
$$\frac{\partial J}{\partial \theta}(\mathbf{x},\mathbf{y},\theta) = -\frac{\partial C}{\partial s}\left(\mathbf{y},s_{\theta}^{\mathbf{x}}\right) \cdot \left(\frac{\partial \mu_{\theta}}{\partial s}\left(\mathbf{x},s_{\theta}^{\mathbf{x}}\right)\right)^{-1} \cdot \frac{\partial \mu_{\theta}}{\partial \theta}\left(\mathbf{x},s_{\theta}^{\mathbf{x}}\right) \text{ones. The basic way to simulate a differential equation on a digital computer is the Euler method in which time is dispersionally
$$\nu(\mathbf{x},\mathbf{y},\theta) = \frac{\partial C}{\partial s}\left(\mathbf{y},s_{\theta}^{\mathbf{x}}\right) \cdot \left(\frac{\partial \mu_{\theta}}{\partial s}\left(\mathbf{x},s_{\theta}^{\mathbf{x}}\right)^{T}\right)^{-1} \cdot \frac{\partial \mu_{\theta}}{\partial \theta}\left(\mathbf{x},s_{\theta}^{\mathbf{x}}\right) \text{cretized. However the discretized dynamics is only an approximation of the true continuous-time dynamics. The ac-$$$$
Theorem 1 is proved in Appendix A. The formulae show that $\nu(x, y, \theta)$ is related to $\frac{\partial J}{\partial \theta}(x, y, \theta)$ and that the angle between these two vectors is directly linked to the 'degree of symmetry' of the Jacobian of $\mu_{\theta}$ at the fixed point $s_{\theta}^{\mathbf{x}}$ .
## **Energy Based Setting as an Idealization** of the Vector Field Setting
We say that $\theta$ is a 'good parameter' if:
- 1. for any initial state for the neurons, the state dynamics $\frac{ds}{dt} = \mu_{\theta}(\mathbf{x}, s)$ converges to a fixed point - a condition required for the algorithm to be correctly defined,
- 2. the scalar product $\frac{\partial J}{\partial \theta}(x, y, \theta) \cdot \nu(x, y, \theta)$ at the point $\theta$ is negative - a desirable condition for the algorithm to optimize the objective function J.
An important particular case is the energy-based setting studied in Scellier and Bengio [2017a], in which the vector field $\mu_{\theta}$ is a gradient field, i.e. $\mu_{\theta}(\mathbf{x},s) = -\frac{\partial E_{\theta}}{\partial s}(\mathbf{x},s)$ for
some scalar function $E_{\theta}(\mathbf{x},s)$ . In this case, the Jacobian of $\mu_{\theta}$ is symmetric since $\frac{\partial \mu_{\theta}}{\partial s} = -\frac{\partial^2 E_{\theta}}{\partial s^2} = \left(\frac{\partial \mu_{\theta}}{\partial s}\right)^T$ , and by Theorem 1 we get $\nu(x,y,\theta) = -\frac{\partial J}{\partial \theta}(x,y,\theta)$ . Therefore, in this setting the set of 'good parameters' is the entire parameter space – for all $\theta$ , the dynamics $\frac{ds}{dt} = -\frac{\partial E_{\theta}}{\partial s}(\mathbf{x}, s)$ converges to a fixed point (a minimum of $E_{\theta}(\mathbf{x}, s)$ ), and $\nu(\mathbf{x}, \mathbf{y}, \boldsymbol{\theta}) \cdot \frac{\partial J}{\partial \boldsymbol{\theta}}(\mathbf{x}, \mathbf{y}, \boldsymbol{\theta}) \leq 0.$
However, for the 'set of good parameters' to cover a large proportion of the parameter space, it is not required that the vector field $\mu_{\theta}$ derives from an energy function $E_{\theta}$ . Indeed, experiments run on the MNIST dataset show that, when $\mu_{\theta}(x, s)$ is defined as in Eq. 6-8, the objective function J consistently decreases (Appendix C). This means that, during training, as the parameter $\theta$ follows the update rule $\Delta\theta \propto \nu(x,y,\theta)$ , all values of $\theta$ that the network takes are 'good parameters'.
### **Possible Implementation on Analog** 6 **Hardware**
Our model is a continuous-time dynamical system (described by differential equations). Digital computers are not well suited to implement such models because they do intrinsically discrete-time computations, not continuous-time a digital computer is the Euler method in which time is dis- $\nu(\mathbf{x}, \mathbf{y}, \theta) = \frac{\partial C}{\partial s} \left( \mathbf{y}, s_{\theta}^{\mathbf{x}} \right) \cdot \left( \frac{\partial \mu_{\theta}}{\partial s} \left( \mathbf{x}, s_{\theta}^{\mathbf{x}} \right)^{T} \right)^{-1} \cdot \frac{\partial \mu_{\theta}}{\partial \theta} \left( \mathbf{x}, s_{\theta}^{\mathbf{x}} \right) \text{ cretized. However the discretized dynamics is only an approximation of the true continuous-time dynamics. The ac$ proximation of the true continuous-time dynamics. The accuracy depends on the size of the discretization step. The bigger the step size, the less acurate the simulation. The smaller the step size, the slower the computations.
> By contrast, analog hardware is ideal for implementing continuous-time dynamics such as those of leaky integrator neurons. Previous work have proposed such implementations [Hertz et al., 1997].
#### 7 **Related Work**
Other alternatives to recurrent back-propagation in the framework of fixed point recurrent networks were proposed by O'Reilly [1996] and Hertz et al. [1997]. Their algorithms are called 'Generalized Recirculation algorithm' (or 'GeneRec' for short) and 'Non-Linear Back-propagation', respectively.
More recently, Mesnard et al. [2016] have adapted Equilibrium Propagation to spiking networks, bringing the model closer to real neural networks. Zenke and Ganguli [2017] also proposed a backprop-like algorithm for supervised learning in spiking networks called 'SuperSpike'. Guerguiev et al. [2017] proposed a mechanism for backpropagating error signals in a multilayer network with com-
<span id="page-4-0"></span> $<sup>^3</sup>$ Recall that $s_{\theta}^{\beta}$ depends on x and y. Hence $\nu$ depends on x and y through $\frac{\partial s_{\theta}^{\beta}}{\partial \beta} \bigg|_{\beta=0}$ .
partment neurons, experimentally shown to learn useful representations.
## 8 Conclusion
Among others, two key features of the backpropagation algorithm make it biologically implausible – the two different kinds of signals sent in the forward and backward phases and the 'weight transport problem'. In this work, we have proposed a backprop-like algorithm for fixed-point recurrent networks, which addresses both these issues. As a key contribution, in contrast to energy-based approaches such as the Hopfield model, we do not impose any symmetry constraints on the neural connections. Our algorithm assumes two phases, the difference between them being whether synaptic changes occur or not. Although this assumption begs for an explanation, neurophysiological findings suggest that phase-dependent mechanisms are involved in learning and memory consolidation in biological systems. Synaptic plasticity, and neural dynamics in general, are known to be modulated by inhibitory neurons and dopamine release, depending on the presence or absence of a target signal [\[Frémaux and Gerstner, 2016,](#page-5-11) [Pawlak et al.,](#page-6-14) [2010\]](#page-6-14).
In its general formulation (Appendix [A\)](#page-6-9), the work presented in this paper is a generalization of Equilibrium Propagation [\[Scellier and Bengio, 2017a\]](#page-6-3) to vector field dynamics. This is achieved by relaxing the requirement of an energy function. This generalization comes at the cost of not being able to compute the (true) gradient of the objective function but, rather a direction in the parameter space which is related to it. Thereby, precision of the approximation of the gradient is directly related to the degree of symmetry of the Jacobian of the vector field.
Our work shows that optimization of an objective function can be achieved without ever computing the (true) gradient. More thorough theoretical analysis needs to be carried out to understand and characterize the dynamics in the parameter space that optimize objective functions. Naturally, the set of all such dynamics is much larger than the tiny subset of gradient-based dynamics.
Our framework provides a means of implementing learning in a variety of physical substrates, whose precise dynamics might not even be known exactly, but which simply have to be in the set of supported dynamics. In particular, this applies to analog electronic circuits, potentially leading to faster, more efficient, and more compact implementations.
## Acknowledgments
The authors would like to thank Blake Richards and Alexandre Thiery for feedback and discussions, as well as NSERC, CIFAR, Samsung, SNSF, and Canada Research Chairs for funding, and Compute Canada for computing resources.
## References
- <span id="page-5-8"></span>L. B. Almeida. A learning rule for asynchronous perceptrons with feedback in a combinatorial environment. volume 2, pages 609–618, San Diego 1987, 1987. IEEE, New York.
- <span id="page-5-1"></span>D. Bahdanau, K. Cho, and Y. Bengio. Neural machine translation by jointly learning to align and translate. *arXiv preprint arXiv:1409.0473*, 2014.
- <span id="page-5-4"></span>Y. Bengio, T. Mesnard, A. Fischer, S. Zhang, and Y. Wu. Stdp-compatible approximation of backpropagation in an energy-based model. *Neural computation*, 29(3):555– 577, 2017.
- <span id="page-5-6"></span>G.-q. Bi and M.-m. Poo. Synaptic modification by correlated activity: Hebb's postulate revisited. *Annual review of neuroscience*, 24(1):139–166, 2001.
- <span id="page-5-7"></span>C. Clopath and W. Gerstner. Voltage and spike timing interact in stdp–a unified model. *Frontiers in synaptic neuroscience*, 2:25, 2010.
- <span id="page-5-2"></span>F. Crick. The recent excitement about neural networks. *Nature*, 337(6203):129–132, 1989.
- <span id="page-5-3"></span>P. Dayan and L. F. Abbott. *Theoretical Neuroscience*. The MIT Press, 2001.
- <span id="page-5-11"></span>N. Frémaux and W. Gerstner. Neuromodulated spiketiming-dependent plasticity, and theory of three-factor learning rules. *Frontiers in neural circuits*, 9:85, 2016.
- <span id="page-5-5"></span>W. Gerstner, R. Kempter, J. L. van Hemmen, and H. Wagner. A neuronal learning rule for sub-millisecond temporal coding. *Nature*, 383(6595):76, 1996.
- <span id="page-5-12"></span>X. Glorot and Y. Bengio. Understanding the difficulty of training deep feedforward neural networks. In *AIS-TATS'2010*, 2010.
- <span id="page-5-10"></span>J. Guerguiev, T. P. Lillicrap, and B. A. Richards. Towards deep learning with segregated dendrites. *ELife*, 6:e22901, 2017.
- <span id="page-5-9"></span>J. Hertz, A. Krogh, B. Lautrup, and T. Lehmann. Nonlinear backpropagation: doing backpropagation without derivatives of the activation function. *IEEE Transactions on neural networks*, 8(6):1321–1327, 1997.
- <span id="page-5-0"></span>G. Hinton, L. Deng, D. Yu, G. E. Dahl, A.-r. Mohamed, N. Jaitly, A. Senior, V. Vanhoucke, P. Nguyen, T. N.
- Sainath, et al. Deep neural networks for acoustic modeling in speech recognition: The shared views of four research groups. *IEEE Signal Processing Magazine*, 29(6): 82–97, 2012.
- <span id="page-6-2"></span>G. E. Hinton and J. L. McClelland. Learning representations by recirculation. In *Neural information processing systems*, pages 358–366, 1988.
- <span id="page-6-4"></span>J. J. Hopfield. Neurons with graded response have collective computational properties like those of two-state neurons. *Proceedings of the national academy of sciences*, 81(10): 3088–3092, 1984.
- <span id="page-6-1"></span>A. Krizhevsky, I. Sutskever, and G. E. Hinton. Imagenet classification with deep convolutional neural networks. In *Advances in neural information processing systems*, pages 1097–1105, 2012.
- <span id="page-6-0"></span>Y. LeCun, Y. Bengio, and G. Hinton. Deep learning. *Nature*, 521(7553):436, 2015.
- <span id="page-6-7"></span>J. Lisman and N. Spruston. Questions about stdp as a general model of synaptic plasticity. Frontiers in synaptic neuroscience, 2:140, 2010.
- <span id="page-6-5"></span>H. Markram and B. Sakmann. Action potentials propagating back into dendrites triggers changes in efficacy. *Soc. Neurosci. Abs*, 21, 1995.
- <span id="page-6-6"></span>H. Markram, W. Gerstner, and P. J. Sjöström. Spike-timing-dependent plasticity: a comprehensive overview. *Frontiers in synaptic neuroscience*, 4:2, 2012.
- <span id="page-6-12"></span>T. Mesnard, W. Gerstner, and J. Brea. Towards deep learning with spiking neurons in energy based models with contrastive hebbian plasticity. *arXiv preprint arXiv:1612.03214*, 2016.
- <span id="page-6-11"></span>R. C. O'Reilly. Biologically plausible error-driven learning using local activation differences: The generalized recirculation algorithm. *Neural computation*, 8(5):895–938, 1996.
- <span id="page-6-14"></span>V. Pawlak, J. R. Wickens, A. Kirkwood, and J. N. Kerr. Timing is not everything: neuromodulation opens the stdp gate. *Frontiers in synaptic neuroscience*, 2:146, 2010.
- <span id="page-6-8"></span>F. J. Pineda. Generalization of back-propagation to recurrent neural networks. *Physical review letters*, 59(19): 2229, 1987.
- <span id="page-6-3"></span>B. Scellier and Y. Bengio. Equilibrium propagation: Bridging the gap between energy-based models and backpropagation. *Frontiers in computational neuroscience*, 11:24, 2017a.
- <span id="page-6-10"></span>B. Scellier and Y. Bengio. Equivalence of equilibrium propagation and recurrent backpropagation. *arXiv* preprint *arXiv*:1711.08416, 2017b.
- <span id="page-6-13"></span>F. Zenke and S. Ganguli. Superspike: Supervised learning in multi-layer spiking neural networks. *arXiv* preprint *arXiv*:1705.11146, 2017.
# **Appendix**
# <span id="page-6-9"></span>A Theorem 1 - General Formulation and Proof
In this appendix, before proving Theorem 1, we first generalize the setting of sections 3 and 4 to the case where the cost function C also depends on the parameter $\theta$ . This is the case e.g. if the cost function includes a regularization term such as $\frac{1}{2}\lambda \|\theta\|^2$ .
## A.1 General Formulation
Recall that we consider the supervised setting in which we want to predict a *target* y given an *input* x. The model is specified by a *state variable* s, a *parameter variable* $\theta$ , a *vector field* in the state space $\mu_{\theta}(x, s)$ and a *cost function* $C_{\theta}(s, y)$ . <sup>4</sup> The stable *fixed point* $s_{\theta}^{x}$ corresponding to the 'prediction' from the model is characterized by
$$\mu_{\theta}\left(\mathbf{x}, s_{\theta}^{\mathbf{x}}\right) = 0. \tag{20}$$
The objective function to be minimized is the cost at the fixed point, i.e.
<span id="page-6-16"></span>
$$J(\mathbf{x}, \mathbf{y}, \theta) := C_{\theta} \left( \mathbf{y}, s_{\theta}^{\mathbf{x}} \right). \tag{21}$$
Traditional methods to compute the gradient of J such as Recurrent Backpropagation are thought to be biologically implausible (see Appendix B). Our approach is to give up on computing the gradient of J and let the parameter variable $\theta$ follow a vector field $\nu$ in the parameter space which approximates the gradient of J.
To this end we first define the augmented vector field
$$\mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s) := \mu_{\theta}(\mathbf{x}, s) - \beta \frac{\partial C_{\theta}}{\partial s}(\mathbf{y}, s). \tag{22} $$
Here $\beta$ is a real-valued scalar which we call *influence parameter*. The corresponding fixed point $s_{\theta}^{\beta}$ is a state at which the augmented vector field vanishes, i.e.
$$\mu_{\theta}^{\beta}\left(\mathbf{x}, \mathbf{y}, s_{\theta}^{\beta}\right) = 0. \tag{23}$$
<span id="page-6-15"></span> $<sup>^4 \</sup>mathrm{In}$ the setting described in section 3, the cost function $C(s,\mathbf{y})$ did not depend on $\theta.$
Under mild regularity conditions on $\mu_{\theta}$ and $C_{\theta}$ , the implicit *Proof of Lemma 2*. First we differentiate the fixed point function theorem ensures that, for a fixed data sample (x, y), the function $(\theta,\beta)\mapsto s_\theta^\beta$ is differentiable.
Then for every $\theta$ we define the vector $\nu(x, y, \theta)$ in the parameter space as
<span id="page-7-1"></span>
$$\nu(\mathbf{x}, \mathbf{y}, \theta) := -\frac{\partial C_{\theta}}{\partial \theta} \left( \mathbf{y}, s_{\theta}^{\mathbf{x}} \right) + \frac{\partial \mu_{\theta}}{\partial \theta} \left( \mathbf{x}, s_{\theta}^{\mathbf{x}} \right)^{T} \cdot \left. \frac{\partial s_{\theta}^{\beta}}{\beta} \right|{\beta = 0}. \tag{24} $$
In section 4 we showed how the second term on the righthand side of Eq. 24 can be estimated with a two-phase training procedure. In the general case where the cost function also depends on the parameter $\theta$ , the definition of the vector $\nu(x,y,\theta)$ contains the new term $-\frac{\partial C_{\theta}}{\partial \theta}(y,s_{\theta}^{x})$ . This extra term can also be measured in a biologically realistic way at the first fixed point $s_{\theta}^{0}$ at the end of the first phase. For example if $C_{\theta}(y, s)$ includes a regularization term such as $\frac{1}{2}\lambda \|\theta\|^2$ , then $\nu(x,y,\theta)$ will include a backmoving force $-\lambda\theta$ , modeling a form of synaptic depression.
We can now reformulate Theorem 1 in a slightly more general form, when the cost function depends on $\theta$ . The gradient of the objective function and the vector field $\nu$ are equal to
$$\frac{\partial J}{\partial \theta}(\theta) = \frac{\partial C{\theta}}{\partial \theta} - \frac{\partial C_{\theta}}{\partial s} \cdot \left(\frac{\partial \mu_{\theta}}{\partial s}\right)^{-1} \cdot \frac{\partial \mu_{\theta}}{\partial \theta},\tag{25}$$
$$\nu(\theta) = -\frac{\partial C_{\theta}}{\partial \theta} + \frac{\partial C_{\theta}}{\partial s} \cdot \left( \left( \frac{\partial \mu_{\theta}}{\partial s} \right)^{T} \right)^{-1} \cdot \frac{\partial \mu_{\theta}}{\partial \theta}. \quad (26)$$
All the factors on the right-hand sides of Eq. 25-26 are evaluated at the fixed point $s_{\theta}^{0}$ . We prove Eq. 25-26 in the next subsection.
#### **A.2 Proof**
In order to prove Eq. 25 and Eq. 26 (i.e. Theorem 1 in a slightly more general form), we first state and prove a lemma.
<span id="page-7-4"></span>**Lemma 2.** Let $s \mapsto \mu_{\theta}^{\beta}(s)$ be a differentiable vector field, and $s_{\theta}^{\beta}$ a fixed point characterized by
<span id="page-7-5"></span>
$$\mu_{\theta}^{\beta}\left(s_{\theta}^{\beta}\right) = 0. \tag{27}$$
Then the partial derivatives of the fixed point are given by
<span id="page-7-6"></span>
$$\frac{\partial s_{\theta}^{\beta}}{\partial \theta} = -\left(\frac{\partial \mu_{\theta}^{\beta}}{\partial s} \left(s_{\theta}^{\beta}\right)\right)^{-1} \cdot \frac{\partial \mu_{\theta}^{\beta}}{\partial \theta} \left(s_{\theta}^{\beta}\right) \tag{28}$$
and
<span id="page-7-7"></span>
$$\frac{\partial s_{\theta}^{\beta}}{\partial \beta} = -\left(\frac{\partial \mu_{\theta}^{\beta}}{\partial s} \left(s_{\theta}^{\beta}\right)\right)^{-1} \cdot \frac{\partial \mu_{\theta}^{\beta}}{\partial \beta} \left(s_{\theta}^{\beta}\right). \tag{29}$$
equation Eq. 27 with respect to $\theta$ :
$$\frac{d}{d\theta} (27) \Rightarrow \frac{\partial \mu_{\theta}^{\beta}}{\partial \theta} \left( s_{\theta}^{\beta} \right) + \frac{\partial \mu_{\theta}^{\beta}}{\partial s} \left( s_{\theta}^{\beta} \right) \cdot \frac{\partial s_{\theta}^{\beta}}{\partial \theta} = 0. \quad (30)$$
Rearranging the terms we get Eq. 28. Similarly we differentiate the fixed point equation Eq. 27 with respect to $\beta$ :
$$\frac{d}{d\beta} (27) \Rightarrow \frac{\partial \mu_{\theta}^{\beta}}{\partial \beta} \left( s_{\theta}^{\beta} \right) + \frac{\partial \mu_{\theta}^{\beta}}{\partial s} \left( s_{\theta}^{\beta} \right) \cdot \frac{\partial s_{\theta}^{\beta}}{\partial \beta} = 0. (31)$$
Rearranging the terms we get Eq. 29.
Now we are ready to prove prove Eq. 25 and Eq. 26.
Proof of Theorem 1 in its general formulation. Let us compute the gradient of the objective function with respect to $\theta$ . Using the chain rule of differentiation we get
$$\frac{\partial J}{\partial \theta} = \frac{\partial C_{\theta}}{\partial \theta} + \frac{\partial C_{\theta}}{\partial s} \cdot \frac{\partial s_{\theta}^{0}}{\partial \theta}. \tag{32} $$
<span id="page-7-2"></span>Hence Eq. 25 follows from Eq. 28 evaluated at $\beta = 0$ . Similarly, the expression for the vector field $\nu$ (Eq. 26) follows from its definition (Eq. 24), the identity Eq. 29 evaluated at $\beta = 0$ and, using Eq. 13, the fact that $\frac{\partial \mu^{\beta}}{\partial \beta} = -\frac{\partial C}{\partial s}$
### <span id="page-7-3"></span><span id="page-7-0"></span>B Link to Recurrent Backpropagation
Earlier work have proposed various methods to compute the gradient of the objective function J (Eq. 21). One of them is Recurrent Backpropagation, an algorithm discovered independently by Almeida [1987] and Pineda [1987]. This algorithm assumes that neurons send a different kind of signals through a different computational path in the second phase, which seems less biologically plausible than our algorithm.
Our approach is to give up on the idea of computing the true gradient of the objective function. Instead our algorithm relies only on the leaky integrator neuron dynamics (Eq. 1) and the STDP-compatible weight change (Eq. 2) and we have shown that it computes a proxy to the true gradient (Theorem 1).
Up to now, we have described our algorithm in terms of fixed points only. In this appendix we study the dynamics itself in the second phase when the state of the network moves from the free fixed point $s_{\theta}^{0}$ to the weakly clamped fixed point $s_{\theta}^{\beta}$ .
The result established in this section is a straightforward generalization of the result proved in Scellier and Bengio [2017b].
### **B.1** Preliminary Notations
We denote by $S_{\theta}^{\mathbf{x}}(\mathbf{s},t)$ the state of the network at time $t \geq 0$ when it starts from an initial state $\mathbf{s}$ at time t = 0 and follows the dynamics of Eq. 9. In the theory of dynamical systems, $S_{\theta}^{\mathbf{x}}(\mathbf{s},t)$ is called the *flow map*. Note that as $t \to \infty$ the dynamics converges to the fixed point $S_{\theta}^{\mathbf{x}}(\mathbf{s},t) \to s_{\theta}^{\mathbf{x}}$ .
Next we define the projected cost function
<span id="page-8-6"></span>
$$L_{\theta}(\mathbf{x}, \mathbf{y}, \mathbf{s}, t) := C_{\theta}(\mathbf{y}, S_{\theta}^{\mathbf{x}}(\mathbf{s}, t)). \tag{33}$$
This is the cost of the state projected a duration t in the future, when the networks starts from s and follows the dynamics of Eq. 9. For fixed $\theta$ , x, y and s, the process $(L_{\theta}(\mathbf{x},\mathbf{y},\mathbf{s},t))_{t\geq 0}$ represents the successive cost values taken by the state of the network along the dynamics when it starts from the initial state s. For t=0, the projected cost is simply the cost of the current state: $L_{\theta}(\mathbf{x},\mathbf{y},\mathbf{s},0)=C_{\theta}(\mathbf{y},\mathbf{s}).$ As $t\to\infty$ the dynamics converges to the fixed point, i.e. $S_{\theta}^{\mathbf{x}}(\mathbf{s},t)\to s_{\theta}^{\mathbf{x}},$ so the projected cost converges to the objective $L_{\theta}(\mathbf{x},\mathbf{y},\mathbf{s},t)\to J(\mathbf{x},\mathbf{y},\theta).$ Under mild regularity conditions on $\mu_{\theta}(\mathbf{x},s)$ and $C_{\theta}(\mathbf{y},s)$ , the gradient of the projected cost function converges to the gradient of the objective function as $t\to\infty$ , i.e.
<span id="page-8-0"></span>
$$\frac{\partial L_{\theta}}{\partial \theta}(\mathbf{x}, \mathbf{y}, \mathbf{s}, t) \to \frac{\partial J}{\partial \theta}(\mathbf{x}, \mathbf{y}, \theta). \tag{34} $$
Therefore, if we can compute $\frac{\partial L_{\theta}}{\partial \theta}(\mathbf{x},\mathbf{y},\mathbf{s},t)$ for a particular value of $\mathbf{s}$ and for any $t\geq 0$ , the desired gradient $\frac{\partial J}{\partial \theta}(\mathbf{x},\mathbf{y},\theta)$ can be obtained by letting $t\to\infty$ . We show next that this is what the Recurrent Backpropagation algorithm does in the case where the initial state $\mathbf{s}$ is the fixed point $s_{\theta}^{\mathbf{x}}$ .
## **B.2** Recurrent Back-Propagation
In order to compute the gradient of J (Eq. 12), the approach of *Recurrent Backpropagation* [Almeida, 1987, Pineda, 1987] is to compute $\frac{\partial L_{\theta}}{\partial \theta}$ (x, y, $s_{\theta}^{x}$ , t) for $t \geq 0$ iteratively. We get the gradient in the limit $t \to \infty$ as a consequence of Eq. 34, when the initial state s is the fixed point $s_{\theta}^{x}$ . <sup>5</sup>
<span id="page-8-2"></span>**Theorem 3** (Recurrent Backpropagation). *Consider the process*
$$\overline{S}t := \frac{\partial L{\theta}}{\partial s} (\mathbf{x}, \mathbf{y}, s_{\theta}^{\mathbf{x}}, t), \qquad t \ge 0, \tag{35} $$
$$\overline{\Theta}t := \frac{\partial L{\theta}}{\partial \theta} (\mathbf{x}, \mathbf{y}, s_{\theta}^{\mathbf{x}}, t), \qquad t \ge 0. \tag{36} $$
We call $(\overline{S}_t, \overline{\Theta}_t)$ the process of error derivatives. It is the
solution of the linear differential equation
<span id="page-8-3"></span>
$$\overline{S}{0} = \frac{\partial C{\theta}}{\partial s} \left( \mathbf{y}, s_{\theta}^{\mathbf{x}} \right), \tag{37}$$
<span id="page-8-7"></span><span id="page-8-5"></span>
$$\overline{\Theta}{0} = \frac{\partial C{\theta}}{\partial \theta} \left( \mathbf{y}, s_{\theta}^{\mathbf{x}} \right), \tag{38}$$
$$\frac{d}{dt}\overline{S}{t} = \frac{\partial \mu{\theta}}{\partial s} \left( \mathbf{x}, s_{\theta}^{\mathbf{x}} \right)^{T} \cdot \overline{S}{t}, \tag{39}$$
$$\frac{d}{dt}\overline{\Theta}{t} = \frac{\partial \mu_{\theta}}{\partial \theta} \left( \mathbf{x}, s_{\theta}^{\mathbf{x}} \right)^{T} \cdot \overline{S}{t}. \tag{40}$$
*Moreover, as* $t \to \infty$
<span id="page-8-4"></span>
$$\overline{\Theta}_t \to \frac{\partial J}{\partial \theta}(\mathbf{x}, \mathbf{y}, \theta). \tag{41} $$
Note that $\overline{S}_t$ takes values in the state space (space of the state variable s) and $\overline{\Theta}_t$ takes values in the parameter space (space of the parameter variable $\theta$ ).
Theorem 3 offers a way to compute the gradient $\frac{\partial J}{\partial \theta}(\mathbf{x},\mathbf{y},\theta)$ . In the first phase, the state variable s follows the dynamics of Eq. 9 and relaxes to the fixed point $s_{\theta}^{\mathbf{x}}$ . Reaching this fixed point is necessary for the computation of the transpose of the Jacobian $\frac{\partial \mu_{\theta}}{\partial s}(\mathbf{x},s_{\theta}^{\mathbf{x}})^T$ which is required in the second phase. In the second phase, the processes $\overline{S}_t$ and $\overline{\Theta}_t$ follow the dynamics determined by Eq. 37-40. As $t \to \infty$ , we have that $\overline{\Theta}_t$ converges to the desired gradient $\frac{\partial J}{\partial \theta}(\mathbf{x},\mathbf{y},\theta)$ .
# **B.3** Temporal Derivatives of Neural Activities in Equilibrium Propagation Approximate Error Derivatives
Two major objections against the biological plausibility of the recurrent backpropagation algorithm are that:
- 1. it is not clear what the quantities $\overline{S}_t$ and $\overline{\Theta}_t$ would represent in a biological network, and
- 2. it is not clear how dynamics such as those of Eq. 37-40 for $\overline{S}_t$ and $\overline{\Theta}_t$ could emerge.
By contrast, Equilibrium Propagation (section 4) does not require specialized dynamics in the second phase. Theorem 1 shows that the gradient $\frac{\partial J}{\partial \theta}(\mathbf{x},\mathbf{y},\theta)$ can be approximated by $\nu(\mathbf{x},\mathbf{y},\theta)$ , which can be itself estimated based on the first and second fixed points. In this section we study the dynamics of the network in the second phase, from the first fixed point to the second fixed point. Although Equilibrium Propagation does not compute explicit error derivatives, we are going to define a process $\left(\widetilde{S}_t,\widetilde{\Theta}_t\right)_{t\geq 0}$ as a function of the dynamics, and show that this process approximates the error derivatives $\left(\overline{S}_t,\overline{\Theta}_t\right)_{t\geq 0}$ .
Let us denote by $S_{\theta}^{\beta}(\mathbf{s},t)$ the state of the network at time $t \geq 0$ when it starts from an initial state s at time t = 0 and
<span id="page-8-1"></span><sup>&</sup>lt;sup>5</sup>The gradient $\frac{\partial L_{\theta}}{\partial \theta}$ (x, y, $s_{\theta}^{x}$ , t) represents the partial derivative of the function L with respect to its first argument, evaluated at the fixed point $s_{\theta}^{x}$ .
follows the dynamics of Eq. 14. In particular, for $\beta=0$ we have $S^0_{\theta}(\mathbf{s},t)=S^{\mathbf{x}}_{\theta}(\mathbf{s},t).$
The state of the network at the beginning of the second phase is the first fixed point $s^0_\theta$ . We choose as origin of time t=0 the moment when the second phase starts: the network is in the state $s^0_\theta$ and the influence parameter takes on a small positive value $\beta \gtrsim 0$ . With our notations, the state of the network at time $t \geq 0$ in the second phase is $S^\beta_\theta(s^0_\theta,t)$ . At time t=0 the network is at the first fixed point, i.e. $S^\beta_\theta(s^0_\theta,0)=s^0_\theta$ , and as $t\to\infty$ the network's state converges to the second fixed point, i.e. $S^\beta_\theta(s,t)\to s^\beta_\theta$ .
Now let us define
$$\widetilde{S}{t} := -\lim_{\beta \to 0} \frac{1}{\beta} \frac{\partial S_{\theta}^{\beta}}{\partial t} \left( s_{\theta}^{0}, t \right), \qquad (42)$$
$$\widetilde{\Theta}{t} := \frac{\partial C{\theta}}{\partial \theta} \left( y, s_{\theta}^{0} \right)$$
$$-\lim_{\beta \to 0} \frac{1}{\beta} \frac{\partial \mu_{\theta}}{\partial \theta} \left( x, s_{\theta}^{0} \right)^{T} \cdot \left( S_{\theta}^{\beta} \left( s_{\theta}^{0}, t \right) - s_{\theta}^{0} \right). \quad (43)$$
First of all note that $S_t$ takes values in the state space and $\widetilde{\Theta}_t$ takes values in the parameter space. From the point of view of biological plausibility, unlike $(\overline{S}_t, \overline{\Theta}_t)$ in Recurrent Backpropagation, the process $(\widetilde{S}_t, \widetilde{\Theta}_t)$ in Equilibrium Propagation has a physiological interpretation. Indeed $\widetilde{S}_t$ is simply the temporal derivative of the neural activity at time t in the second phase (rescaled by a factor $\frac{1}{\beta}$ ). As for $\widetilde{\Theta}_t$ , the first term is zero in the case of the quadratic cost (Eq. 11) $^6$ and the second term corresponds to the STDP-compatible weights change (Eq. 5) integrated between the initial state (the first fixed point) and the state at time t in the second phase (and rescaled by a factor $\frac{1}{\beta}$ ). For short, we call $(\widetilde{S}_t, \widetilde{\Theta}_t)$ the process of temporal derivatives.
<span id="page-9-1"></span>**Theorem 4.** The process of temporal derivatives $(\widetilde{S}_t, \widetilde{\Theta}_t)$ satisfies
$$\widetilde{S}0 = \frac{\partial C{\theta}}{\partial s} (\mathbf{y}, s_{\theta}^{\mathbf{x}}), \tag{44} $$
$$\widetilde{\Theta}{0} = \frac{\partial C{\theta}}{\partial \theta} \left( \mathbf{y}, s_{\theta}^{\mathbf{x}} \right), \tag{45}$$
$$\frac{d}{dt}\widetilde{S}{t} = \frac{\partial \mu{\theta}}{\partial s} \left( \mathbf{x}, s_{\theta}^{\mathbf{x}} \right) \cdot \widetilde{S}{t}, \tag{46}$$
$$\frac{d}{dt}\widetilde{\Theta}{t} = \frac{\partial \mu_{\theta}}{\partial \theta} \left( \mathbf{x}, s_{\theta}^{\mathbf{x}} \right)^{T} \cdot \widetilde{S}{t}. \tag{47}$$
Furthermore, as $t \to \infty$
$$\widetilde{\Theta}_t \to \nu(\mathbf{x}, \mathbf{y}, \theta). \tag{48} $$
Theorem 3 and Theorem 4 show that the processes $(\overline{S}_t, \overline{\Theta}_t)$ and $(\widetilde{S}_t, \widetilde{\Theta}_t)$ satisfy related differential equations. The difference between the dynamics of Theorem 3 and Theorem 4 lies in Eq. 39 and Eq. 46.
As in Theorem 1, the discrepancy between these processes is directly linked to the 'degree of symmetry' of the Jacobian of $\mu_{\theta}$ . Again, an important particular case is the energy-based setting in which $\mu_{\theta} = -\frac{\partial E_{\theta}}{\partial s}$ for some scalar function $E_{\theta}(\mathbf{x},s)$ . In this case $\frac{\partial \mu_{\theta}}{\partial s} = -\frac{\partial^2 E_{\theta}}{\partial s^2} = \left(\frac{\partial \mu_{\theta}}{\partial s}\right)^T$ , and by Theorems 3 and 4 we get $\widetilde{S}_t = \overline{S}_t$ and $\widetilde{\Theta}_t = \overline{\Theta}_t$ . This result was stated and proved in Scellier and Bengio [2017b].
## **B.4** Proofs of Theorems 3 and 4
*Proof of Theorem 3.* First of all, by definition of L (Eq. 33) we have $L_{\theta}(\mathbf{s},0) = C_{\theta}(\mathbf{s})$ . Therefore the initial conditions (Eq. 37 and Eq. 38) are satisfied:
$$\frac{\partial L{\theta}}{\partial s} \left( s_{\theta}^{0}, 0 \right) = \frac{\partial C_{\theta}}{\partial s} \left( s_{\theta}^{0} \right) \tag{49}$$
and
$$\frac{\partial L_{\theta}}{\partial \theta} \left( s_{\theta}^{0}, 0 \right) = \frac{\partial C_{\theta}}{\partial \theta} \left( s_{\theta}^{0} \right). \tag{50}$$
Now we show that $\overline{S}_t = \frac{\partial L}{\partial s} \left( s^0, t \right)$ satisfies the differential equation (Eq. 39). We omit to write the dependence in $\theta$ to keep notations simple. As a preliminary result, we show that for all initial state s and time t we have <sup>7</sup>
<span id="page-9-5"></span>
$$\frac{\partial L}{\partial t}(\mathbf{s}, t) = \frac{\partial L}{\partial s}(\mathbf{s}, t) \cdot \mu(\mathbf{s}). \tag{51}$$
To this end note that (by definition of L and $S^0$ ) we have for all t and u
<span id="page-9-4"></span>
$$L\left(S^{0}(\mathbf{s}, u), t\right) = L(\mathbf{s}, t + u). \tag{52}$$
<span id="page-9-6"></span>The derivatives of the right-hand side of Eq. 52 with respect to t and u are clearly equal:
$$\frac{d}{dt}L(\mathbf{s},t+u) = \frac{d}{du}L(\mathbf{s},t+u). \tag{53}$$
<span id="page-9-8"></span><span id="page-9-7"></span><span id="page-9-2"></span>Therefore the derivatives of the left-hand side of Eq. 52 are equal too:
$$\frac{\partial L}{\partial t} \left( S^{0}(\mathbf{s}, u), t \right) = \frac{d}{du} L \left( S^{0}(\mathbf{s}, u), t \right)
= \frac{\partial L}{\partial s} \left( S^{0}(\mathbf{s}, u), t \right) \cdot \mu \left( S^{0}(\mathbf{s}, u), t \right). \tag{54} $$
<span id="page-9-0"></span><sup>&</sup>lt;sup>6</sup>If the cost function includes a regularization term of the form $\frac{1}{2} \|\theta\|^2$ , the first term is a backmoving force $-\lambda\theta$ modeling a form of synaptic depression.
<span id="page-9-3"></span><sup>&</sup>lt;sup>7</sup>Eq. 51 is the Kolmogorov backward equation for a deterministic pro-
Here we have used the differential equation of motion (Eq. 9). Evaluating this expression for u=0 we get Eq. 51. Then, differentiating Eq. 51 with respect to s, we get
$$\frac{\partial^2 L}{\partial t \partial s}(\mathbf{s}, t) = \frac{\partial^2 L}{\partial s^2}(\mathbf{s}, t) \cdot \mu(\mathbf{s}) + \left(\frac{\partial \mu}{\partial s}(\mathbf{s})\right)^T \cdot \frac{\partial L}{\partial s}(\mathbf{s}, t). \tag{56} $$
Evaluating this expression at the fixed point $s=s^0$ and using the fixed point condition $\mu(s^0)=0$ we get
$$\frac{d}{dt}\frac{\partial L}{\partial s}\left(s^{0},t\right) = \left(\frac{\partial \mu}{\partial s}\left(s^{0}\right)\right)^{T} \cdot \frac{\partial L}{\partial s}\left(s^{0},t\right). \tag{57}$$
Therefore $\frac{\partial L}{\partial s}(s^0,t)$ satisfies Eq. 39.
Finally we prove Eq. 40. Differentiating Eq. 51 with respect to $\theta$ , we get
$$\frac{\partial^2 L_{\theta}}{\partial t \partial \theta} (\mathbf{s}, t) = \frac{\partial^2 L_{\theta}}{\partial s \partial \theta} (\mathbf{s}, t) \cdot \mu_{\theta}(\mathbf{s}) \tag{58} $$
$$+ \left(\frac{\partial \mu_{\theta}}{\partial \theta}(\mathbf{s})\right)^{T} \cdot \frac{\partial L_{\theta}}{\partial s}(\mathbf{s}, t). \tag{59}$$
Evaluating this expression at the fixed point $s=s_{\theta}^{0}$ we get
$$\frac{d}{dt}\frac{\partial L_{\theta}}{\partial \theta}\left(s_{\theta}^{0}, t\right) = \left(\frac{\partial \mu_{\theta}}{\partial \theta}\left(s_{\theta}^{0}\right)\right)^{T} \cdot \frac{\partial L_{\theta}}{\partial s}\left(s_{\theta}^{0}, t\right). \tag{60}$$
Hence the result. $\Box$
Proof of Theorem 4. First of all, note that
$$\frac{\partial^{2} S_{\theta}^{\beta}}{\partial \beta \partial t} \bigg|{\beta=0} \left( s{\theta}^{0}, t \right) = \lim_{\beta \to 0} \frac{1}{\beta} \left( \frac{\partial S_{\theta}^{\beta}}{\partial t} \left( s_{\theta}^{0}, t \right) - \frac{\partial S_{\theta}^{0}}{\partial t} \left( s_{\theta}^{0}, t \right) \right) \tag{61}$$
$$= \lim_{\beta \to 0} \frac{1}{\beta} \frac{\partial S_{\theta}^{\beta}}{\partial t} \left( s_{\theta}^{0}, t \right). \tag{62}$$
This is because $S^0_{\theta}\left(s^0_{\theta},t\right)=s^0_{\theta}$ for every $t\geq 0$ , so that $\frac{\partial S^0_{\theta}}{\partial t}\left(s^0_{\theta},t\right)=0$ at every moment $t\geq 0$ . Furthermore
$$\frac{\partial C_{\theta}}{\partial \theta} \left( s_{\theta}^{0} \right) - \frac{\partial \mu_{\theta}}{\partial \theta} \left( s_{\theta}^{0} \right)^{T} \cdot \left. \frac{\partial S_{\theta}^{\beta}}{\partial \beta} \right|{\theta = 0} \left( s{\theta}^{0}, t \right) \tag{63}$$
$$= \frac{\partial C_{\theta}}{\partial \theta} \left( s_{\theta}^{0} \right) - \lim_{\beta \to 0} \frac{1}{\beta} \left( \frac{\partial \mu_{\theta}}{\partial \theta} \left( s_{\theta}^{0} \right)^{T} \cdot \left( S_{\theta}^{\beta} \left( s_{\theta}^{0}, t \right) - s_{\theta}^{0} \right) \right)$$ \tag{64} $$$$
Thus, we have to show that the process $(\widetilde{S}_t, \widetilde{\Theta}_t)$ defined as
$$\widetilde{S}t := -\left. \frac{\partial^2 S\theta^\beta}{\partial \beta \partial t} \right|{\beta=0} \left( s\theta^0, t \right), \tag{65}$$
$$\widetilde{\Theta}{t} := \frac{\partial C{\theta}}{\partial \theta} \left( s_{\theta}^{0} \right) + \frac{\partial \mu_{\theta}}{\partial \theta} \left( s_{\theta}^{0} \right)^{T} \cdot \left. \frac{\partial S_{\theta}^{\beta}}{\partial \beta} \right|{\beta = 0} \left( s{\theta}^{0}, t \right) \quad (66)$$
satisfies Eq. 44, Eq. 45, Eq. 46 and Eq. 47.
First we prove the result for $S_t$ . We omit to write the dependence in $\theta$ to keep notations simple. The process $\left(S^{\beta}(\mathbf{s},t)\right)_{t\geq 0}$ is solution of the differential equation
<span id="page-10-1"></span>
$$\frac{\partial S^{\beta}}{\partial t}(\mathbf{s},t) = \mu^{\beta} \left( S^{\beta}(\mathbf{s},t) \right). \tag{67}$$
with initial condition $S^{\beta}(s,0) = s$ . Differentiating Eq. 67 with respect to $\beta$ , we get the following equation for the process $\frac{\partial S^{\beta}}{\partial \beta}(s,t)$ :
$$\frac{d}{dt}\frac{\partial S^{\beta}}{\partial \beta}(\mathbf{s},t) = \frac{\partial \mu^{\beta}}{\partial \beta} \left( S^{\beta}(\mathbf{s},t) \right) + \frac{\partial \mu^{\beta}}{\partial s} \left( S^{\beta}(\mathbf{s},t) \right) \cdot \frac{\partial S^{\beta}}{\partial \beta}(\mathbf{s},t). \tag{68} $$
Evaluating at $\beta=0$ , taking $\mathbf{s}=s^0$ as an initial state and using the fact that $S^0\left(s^0,t\right)=s^0$ , we get
<span id="page-10-2"></span>
$$\frac{d}{dt} \left. \frac{\partial S^{\beta}}{\partial \beta} \right|{\beta=0} (s^{0}, t) = -\frac{\partial C}{\partial s} (s^{0}) + \frac{\partial \mu}{\partial s} (s^{0}) \cdot \frac{\partial S^{\beta}}{\partial \beta} \right|{\beta=0} (s^{0}, t).$$
Since $S^{\beta}(s,0) = s$ is independent of $\beta$ , we have $\frac{\partial S^{\beta}}{\partial \beta}(s,0) = 0$ . Therefore, evaluating Eq. 69 at t=0, we get the initial condition (Eq. 44):
$$\left. \frac{\partial^2 S^{\beta}}{\partial t \partial \beta} \right|{\beta=0} \left( s^0, 0 \right) = -\frac{\partial C}{\partial s} \left( s^0 \right). \tag{70}$$
Moreover, differentiating Eq. 69 with respect to time we get Eq. 46:
$$\frac{d}{dt} \left. \frac{\partial^2 S^{\beta}}{\partial t \partial \beta} \right|{\beta=0} (s^0, t) = \frac{\partial \mu}{\partial s} (s^0) \cdot \left. \frac{\partial^2 S^{\beta}}{\partial t \partial \beta} \right|{\beta=0} (s^0, t). \tag{71} $$
Now we prove the result for $\widetilde{\Theta}_t$ . Evaluating Eq. 66 at time t = 0 we get the initial condition (Eq. 45)
$$\widetilde{\Theta}_0 = \frac{\partial C\theta}{\partial \theta} \left( s_\theta^0 \right). \tag{72}$$
Moreover, differentiating Eq. 66 with respect to time we get Eq. 47:
$$\frac{d}{dt}\widetilde{\Theta}{t} = -\frac{\partial \mu{\theta}}{\partial \theta} \left(s_{\theta}^{0}\right)^{T} \cdot \left. \frac{\partial^{2} S_{\theta}^{\beta}}{\partial t \partial \beta} \right|{\beta=0} \left(s{\theta}^{0}, t\right). \tag{73}$$
Hence the result. $\Box$
# <span id="page-10-0"></span>C Experiments and Implementation of the Model
<span id="page-10-3"></span>Our model is a recurrently connected neural network without any constraint on the feedback weight values (unlike models such as the Hopfield network). We train multilayered networks with 2 or 3 hidden layers on the MNIST
<span id="page-11-3"></span>
| Architecture | Iterations<br>Iterations | | | β | α1 | α2 | α3 | α4 |
|----------------------------|---------------------------------|-----|-------|-----|-----|-----|------|-------|
| | (first phase)<br>(second phase) | | | | | | | |
| 784 − 512 − 512 − 10 | 200 | 100 | 0.001 | 1.0 | 0.4 | 0.1 | 0.01 | −− |
| 784 − 512 − 512 − 512 − 10 | 200 | 100 | 0.001 | 1.0 | 1.0 | 0.1 | 0.04 | 0.002 |
Table 1: Hyperparameters for both the 2- and 3-layer networks trained on the MNIST dataset, as described in Appendix [C.](#page-10-0) The objective function is optimized: the training error decreases to 0.00%. The generalization error lies between 2% and 3% depending on the architecture. The learning rate is used for iterative inference (Eq. [77\)](#page-11-1). β is the value of the influence parameter in the second phase. α<sup>k</sup> is the learning rate for updating the parameters in layer k.
| Operation | Kernel | Strides | Feature Maps | Non Linearity |
|-------------|--------|---------|--------------|---------------|
| Convolution | 5 x 5 | 1 | 32 | Relu |
| Convolution | 5 x 5 | 1 | 64 | Relu |
Table 2: Hyperparameters for MNIST CNN experiments.
<span id="page-11-4"></span>task, with no skip-layer connections and no lateral connections within layers, as in Figure [3](#page-11-0) (though the theory presented in this paper applies to any network architecture).
Rather than performing weight updates at all time steps in the second phase, we perform a single update at the end of the second phase:
$$\Delta W_{ij} \propto \frac{\partial \mu_{\theta}}{\partial W_{ij}} \left( \mathbf{x}, s_{\theta}^{0} \right)^{T} \cdot \frac{s_{\theta}^{\beta} - s_{\theta}^{0}}{\beta}. \tag{74}$$
The predicted value (given the input x) is read on the last layer at the first fixed point s 0 0 at the end of the first phase. The predicted value <sup>y</sup><sup>b</sup> is the index of the output unit whose activation is maximal among the 10 output units:
$$\widehat{y} := \underset{i}{\operatorname{arg\,max}} \ s_{0,i}^{0}. \tag{75}$$
Implementation of the neuronal dynamics. We start by clamping x to the data values. Then we use the Euler method to implement Eq. [14.](#page-3-2) The naive method is to discretize time into short time lapses of duration and to update the state variable s iteratively thanks to
<span id="page-11-2"></span>
$$s \leftarrow s - \epsilon \ \mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s). \tag{76} $$
For our experiments, we choose the hard sigmoid activation function ρ(si) = 0∨s^{i} ∧1, where ∨ denotes the max and ∧ the min. To address stability issues, we restrict the range of values for the neurons' states and clip them between 0 and 1. Thus, rather than the standard Euler method (Eq. [76\)](#page-11-2), we use a slightly different update rule for the state variable s:
<span id="page-11-1"></span>
$$s \leftarrow 0 \lor \left(s - \epsilon \ \mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s)\right) \land 1. \tag{77} $$
We use different learning rates for different layers in our experiments. The hyperparameters chosen for each model are shown in Table 1. We initialize the weights according to the Glorot-Bengio initialization [Glorot and Bengio, 2010]. For efficiency of the experiments, we use minibatches of 20 training examples.
We were also able to train on MNIST using a Convolutional Neural Network (CNN). We got around 2% generalization error. The hyperparameters chosen to train this Convolutional Neural Network are shown in Table 2.
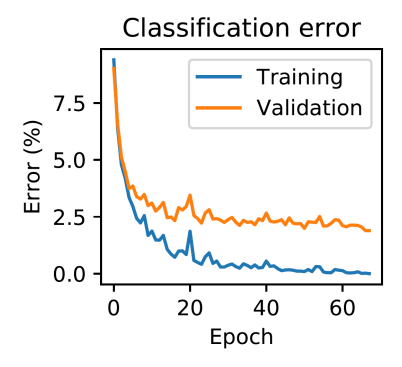
Figure 3: Experiments on the MNIST dataset.