Generalization of Equilibrium Propagation to Vector Field Dynamics
作者: Benjamin Scellier, Anirudh Goyal, Jonathan Binas, Thomas Mesnard, Yoshua Bengio (Mila, Université de Montréal)
日期: 2018年8月
摘要
反向传播算法(Backpropagation)的生物学合理性一直受到神经科学家的质疑。主要原因包括:
1. 神经元需要在前向和后向阶段发送两种不同类型的信号。
2. 神经元对需要通过对称的双向连接进行通信。
本文提出了一种用于不动点循环网络(Fixed Point Recurrent Networks)的简单两阶段学习过程,解决了上述问题。在该模型中,神经元执行泄漏积分(leaky integration),突触权重通过局部机制更新。该方法将均衡传播(Equilibrium Propagation)推广到了向量场动力学(Vector Field Dynamics),放宽了对能量函数的需求。因此,该算法计算的不是目标函数的真实梯度,而是一个近似值,其精度被证明与前馈和反馈权重的对称程度直接相关。实验表明该算法能够优化目标函数。
1. 引言
深度学习虽然在多个领域取得了巨大成功,但大脑皮层是否实现了类似反向传播的机制仍然是一个悬而未决的问题。反向传播通常需要一个专门的侧向网络来传播误差导数,这在生物学上被认为是不可信的。
均衡传播(Equilibrium Propagation) [Scellier and Bengio, 2017a] 虽然不需要侧向网络,但原始版本要求网络动力学源自能量函数(Hopfield能量),这意味着神经元之间的连接必须是对称的($W_{ij} = W_{ji}$),这在生物学上也是不现实的。
本文提出的方法是对均衡传播的推广,不再需要能量函数、梯度动力学或对称连接。
2. 神经动力学 (Neuronal Dynamics)
2.1 神经元模型 (Neuron Model)
我们使用 $s_i$ 表示神经元 $i$ 的膜电压(状态变量),$\rho(s_i)$ 表示其发放率(非线性激活函数)。
神经元膜电压 $s_i$ 的时间演化遵循基于速率的泄漏积分器模型(rate-based leaky integrator neuron model):
$$ \frac{ds_i}{dt} = \sum_j W_{ij} \rho(s_j) - s_i \tag{1} $$
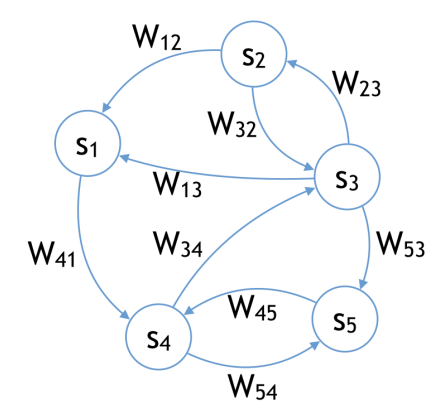
与Hopfield模型不同,这里的连接权重 $W_{ij}$ 不需要是对称的。模型是一个有向图。
| (a) 本文模型(有向图) | (b) Hopfield模型(无向图) |
|---|---|
 |
 |
| 图 1: (a) 本文研究的模型像生物神经网络一样是有向图。(b) Hopfield模型最好被视为无向图,其连接对称性是生物学合理性的主要缺陷。 |
2.2 可塑性模型 (Plasticity Model)
我们考虑一种基于突触前和突触后活动的简化Hebbian更新规则。突触后活动的变化 $ds_i$ 导致突触强度 $dW_{ij}$ 的变化:
$$ dW_{ij} \propto \rho(s_j)ds_i \tag{2} $$
这被称为STDP兼容的权重变化(STDP-compatible weight change)。
2.3 状态空间中的向量场 $\mu$
定义全局状态变量 $s = (s_1, s_2, \dots)$ 和参数变量 $\theta = (W_{ij})_{i,j}$。定义向量场 $\mu_\theta(s)$,其分量为:
$$ \mu_{\theta,i}(s) := \sum_{j} W_{ij} \rho(s_j) - s_i \tag{3} $$
于是,神经元动力学方程 (1) 可以重写为:
$$ \frac{ds}{dt} = \mu_{\theta}(s) \tag{4} $$
STDP兼容的权重变化 (2) 可以重写为更简洁的形式:
$$ d\theta \propto \frac{\partial \mu_{\theta}}{\partial \theta} (s)^T \cdot ds \tag{5} $$
3. 用于监督学习的不动点循环神经网络
在监督学习设定中,给定输入 $x$ 预测目标 $y$。网络单元分为:
* 输入单元 $x$:值被固定(clamped)。
* 动态演化单元 $s$:包括隐藏层(如 $s_1, s_2$)和输出层($s_0$)。
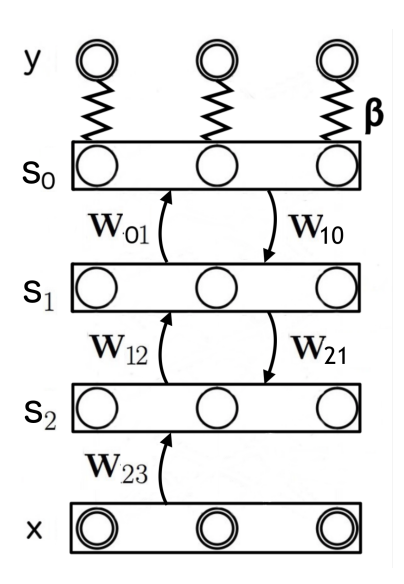
图 2: 网络结构图。输入 $x$ 被固定。神经元 $s$ 包括隐藏层 $s_2, s_1$ 和输出层 $s_0$。目标 $y$ 维度与 $s_0$ 相同。
向量场 $\mu_\theta$ 定义如下(以图示结构为例):
$$
\begin{aligned}
\mu_{\theta,0}(\mathbf{x},s) &= W_{01} \cdot \rho(s_1) - s_0 \quad &(6) \\
\mu_{\theta,1}(\mathbf{x},s) &= W_{12} \cdot \rho(s_2) + W_{10} \cdot \rho(s_0) - s_1 \quad &(7) \\
\mu_{\theta,2}(\mathbf{x},s) &= W_{23} \cdot \rho(\mathbf{x}) + W_{21} \cdot \rho(s_1) - s_2 \quad &(8)
\end{aligned}
$$
神经元 $s$ 遵循动力学:
$$
\frac{ds}{dt} = \mu_{\theta}(\mathbf{x}, s) \tag{9}
$$
假设动力学收敛到一个不动点 $s_{\theta}^{\mathbf{x}}$,满足:
$$
\mu_{\theta}\left(\mathbf{x}, s_{\theta}^{\mathbf{x}}\right) = 0 \tag{10}
$$
目标函数:
定义代价函数 $C(y, s)$ 衡量状态 $s$ 与目标 $y$ 的差异(通常仅涉及输出层 $s_0$):
$$
C(y,s) = \frac{1}{2} \|y - s_0\|^2 \tag{11}
$$
我们要最小化的目标函数 $J$ 是不动点处的代价:
$$
J(\mathbf{x}, \mathbf{y}, \theta) := C(\mathbf{y}, s_{\theta}^{\mathbf{x}}) \tag{12}
$$
4. 向量场设置下的均衡传播 (Equilibrium Propagation)
4.1 增强向量场 (Augmented Vector Field)
核心思想是将代价函数 $C$ 视为输出层 $s_0$ 的“外部势能”。定义增强向量场:
$$ \mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s) := \mu_{\theta}(\mathbf{x}, s) - \beta \frac{\partial C}{\partial s}(\mathbf{y}, s) \tag{13} $$
其中 $\beta \ge 0$ 是影响参数(influence parameter)或钳制因子。
新的动力学方程为:
$$ \frac{ds}{dt} = \mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s) \tag{14} $$
- 当 $\beta=0$ 时,对应原始动力学,收敛到不动点 $s_{\theta}^{0} = s_{\theta}^{\mathbf{x}}$。
- 当 $\beta > 0$ 时,外部力 $-\beta \frac{\partial C}{\partial s}$ 会将输出层 $s_0$ 推向目标 $y$。系统收敛到新的不动点 $s_{\theta}^{\beta}$,满足 $\mu_{\theta}^{\beta}(\mathbf{x}, \mathbf{y}, s_{\theta}^{\beta}) = 0$。
4.2 算法流程
这是一个两阶段学习过程:
-
第一阶段(预测阶段):
- 输入 $x$ 固定,$\beta = 0$。
- 状态 $s$ 演化至不动点 $s_{\theta}^{0}$。
- 突触权重保持不变。
-
第二阶段(训练阶段):
- 输入 $x$ 仍固定,$\beta$ 设为一个小的正值 ($\beta \gtrsim 0$)。
- 状态 $s$ 演化至新的不动点 $s_{\theta}^{\beta}$。
- 突触权重根据 STDP 兼容规则更新(见下文)。
- 外部力作用于输出层,产生的扰动反向传播至隐藏层,形成“误差信号”。
5. 目标函数的优化
5.1 参数空间中的向量场 $\nu$
在第二阶段,状态从 $s_{\theta}^{0}$ 移动到 $s_{\theta}^{\beta}$。对权重更新规则 (Eq. 5) 进行积分并归一化,得到参数更新方向:
$$ \Delta\theta \propto \nu(x, y, \theta) \tag{18} $$
其中向量 $\nu$ 定义为:
$$ \nu(\mathbf{x}, \mathbf{y}, \theta) := \frac{\partial \mu_{\theta}}{\partial \theta} \left( \mathbf{x}, s_{\theta}^{0} \right)^{T} \cdot \left. \frac{\partial s_{\theta}^{\beta}}{\partial \beta} \right|_{\beta = 0} \tag{19} $$
5.2 向量场 $\nu$ 作为梯度的代理 (Proxy)
定理 1:梯度 $\frac{\partial J}{\partial \theta}$ 和向量场 $\nu$ 之间存在如下关系:
$$ \frac{\partial J}{\partial \theta} = -\frac{\partial C}{\partial s} \cdot \left(\frac{\partial \mu_{\theta}}{\partial s}\right)^{-1} \cdot \frac{\partial \mu_{\theta}}{\partial \theta} $$
$$ \nu = \frac{\partial C}{\partial s} \cdot \left(\left(\frac{\partial \mu_{\theta}}{\partial s}\right)^{T}\right)^{-1} \cdot \frac{\partial \mu_{\theta}}{\partial \theta} $$
(注:上述公式中各导数均在不动点 $s_{\theta}^{\mathbf{x}}$ 处求值)
这表明 $\nu$ 与真实梯度 $\frac{\partial J}{\partial \theta}$ 之间的角度取决于雅可比矩阵 $\frac{\partial \mu_{\theta}}{\partial s}$ 的对称程度。
- 能量基模型(理想情况):如果 $\mu_\theta$ 是梯度场(即存在能量函数 $E$ 使得 $\mu_\theta = -\nabla_s E$),则雅可比矩阵是对称的。此时 $\nu = -\frac{\partial J}{\partial \theta}$,算法执行精确的梯度下降。
- 向量场模型(一般情况):虽然不完全平行于梯度,但实验表明 $\nu$ 仍然是一个好的下降方向,能够优化目标函数。
6. 实验与实现
MNIST 实验
作者在MNIST数据集上训练了全连接网络和卷积神经网络(CNN)。
* 架构:无跳跃连接,无层内侧向连接(尽管理论支持任意架构)。
* 更新规则:在第二阶段结束时执行一次更新:
$$
\Delta W_{ij} \propto \frac{\partial \mu_{\theta}}{\partial W_{ij}} \left( \mathbf{x}, s_{\theta}^{0} \right)^{T} \cdot \frac{s_{\theta}^{\beta} - s_{\theta}^{0}}{\beta} \tag{74}
$$
* 实现细节:使用欧拉法模拟微分方程。为了稳定性,使用了硬Sigmoid激活函数并将状态裁剪在[0, 1]之间。
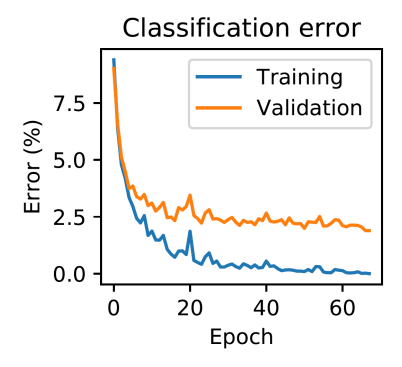
图 3: MNIST数据集上的实验结果。
结论
该工作展示了在不计算真实梯度的情况下,通过放宽能量函数的限制,利用向量场动力学也能有效地优化目标函数。这为在模拟硬件(如神经形态芯片)上实现更高效、更紧凑的学习算法提供了理论基础。